
CV Deep Dive
Today, we’re talking with Sid Sheth, co-founder and CEO of d-Matrix.
d-Matrix is tackling AI inference with its novel Digital In-Memory Compute (DIMC) architecture to boost efficiency and speed for generative AI workloads in cloud data centers. Founded in 2019, d-Matrix is targeting the growing demand for AI inference, building what Sid describes as “the most efficient computing platform for AI inference” by focusing on customer-driven innovation and first-principles engineering.
Key Takeaways:
Inference Dominance: d-Matrix bet early on inference becoming the dominant AI computing challenge, a vision validated by the explosion of generative AI demand.
DIMC Innovation: The DIMC architecture combines digital accuracy with in-memory compute efficiency, chiplet based scaling and block floating point numerics, achieving industry-leading performance, energy efficiency and throughput.
Future Expansion: While currently focused on cloud data centers, d-Matrix envisions scaling it’s chiplet-based platform into workstations and client PCs in the future.
Sid brings a wealth of experience to d-Matrix, having incubated and grown Marvell’s data center business into a $2B revenue generator after a $10B acquisition. He has a proven track record as a serial entrepreneur with a passion for building companies from scratch.
The company has raised $160 million from top investors and strategic partners including Playground Global, M12 (Microsoft Venture Fund), Temasek, Triatomic Capital, Nautilus Venture Partners, Entrada Ventures, Industry Ventures, Ericsson Ventures, Mirae Asset, SK Hynix , Lam Capital and Foothill Ventures.
In this conversation, Sid explains d-Matrix’s DIMC, the competitive landscape of AI inference, and his personal journey as a multi-time founder.
Let’s dive in ⚡️
Read time: 8 mins
Our Chat with Sid 💬
Welcome to Cerebral Valley, Sid! Can you tell us a bit about your background and what ultimately led you to become a multiple-time founder?
Hey thanks for having me! So a quick note on my background. I grew up in India, and I come from a family of entrepreneurs going back to my paternal and maternal grandfathers, both back to the 1940s. They both started pretty young as entrepreneurs, and my dad was an entrepreneur in the 1970s. So I think there’s definitely some DNA in the family that pushed me toward becoming a serial entrepreneur myself.
I came to the US in the mid-90s and went to Purdue for my electrical and computer engineering degree. After that, I joined Intel, where I spent about four or five years learning the basics. That experience was really formative because it taught me that a big company environment just wasn’t for me. I wanted to be somewhere I could make a bigger impact, create something from scratch, and be part of the creative process.
I quickly realized that I loved going from zero to one—taking nothing and turning it into something. I got the opportunity to join a group of folks in 2001 to help kick-start a company called Aeluros, which was working on 10 gig Ethernet connectivity chips. That journey lasted about 10 years and included a couple of acquisitions: first by NetLogic Microsystems in 2007 and then by Broadcom in 2011.
After those early entrepreneurial ventures, what were the key milestones in your journey leading up to founding d-Matrix, and what motivated you to focus on AI inference?
After the Broadcom acquisition, I joined Inphi in 2011. They brought me on to incubate their data center business, which was a unique opportunity to build a new business within a public company. We grew that business over nine years, and it’s now running at over $2 billion in revenue as part of Marvell. Marvell acquired the business in a $10 billion deal in 2021, and it remains a flagship part of their portfolio.
In 2019, I co-founded d-Matrix with the goal of building a company that would last—something that could outlive us. We wanted to solve big, relevant problems for major customers, and AI inference stood out as the most critical computing problem of our time.
When we started, our thesis was that inference—not training—would become the dominant computing challenge over the next 10 to 20 years. At the time, most people believed CPUs and GPUs would handle the job, but we saw the need for a dedicated platform for inference. We decided to focus entirely on building the world’s most efficient computing platform for AI inference, going back to first principles to figure out what that would look like.
We made key bets along the way—focusing on transformer acceleration, in-memory computing techniques, chiplet-based architectures, and open software stacks. These decisions shaped our platform into what it is today: what we believe is the world’s best platform for generative AI inference. Now, five and a half years later, we’re launching our product, and we’re confident it represents the future of AI inference computing.
How would you describe d-Matrix to the uninitiated?
d-Matrix is an AI chip company that optimizes for AI inferencing rather than training. We created Digital In-Memory Compute (DIMC), a unique architecture optimized for AI inference. Our platform improves efficiency, speed, and accuracy by performing computations directly in memory, reducing the need to move data around. This approach is designed specifically for handling large-scale inference workloads in data centers.
When you started d-Matrix in 2019, you bet on AI inference becoming a critical before the compute demand of LLMs existed. What gave you confidence in this direction?
That’s a great question. When we started, we knew building a chip company required solving a major, validated customer problem. Hardware is tough, chips even tougher, and the investment needed to build a chip company is massive. So we spent the first two years talking to customers and validating our thesis.
What we learned was that while training models was the focus at the time, inference would eventually dominate. Customers told us, “Training gets you the intelligent models, but scaling and deploying them in the real world will be the bigger challenge.” And logically, it made sense—models are trained a finite number of times, but they’re used for inference endlessly.
We thought of it like human development: you spend a few decades training and learning, but most of your life is spent applying that knowledge. AI is no different. So, we made the bet that inference would be the bigger computing opportunity, even though it wasn’t urgent yet.
We thought it might take longer, but then ChatGPT came along, and suddenly, inference was the talk of the town. That shift happened much faster than we expected, and it completely validated the direction we’d taken.
Can you explain what d-Matrix’s DIMC (Digital In-Memory Compute) architecture is, how it evolved, and why you chose this approach over others?
DIMC is one of our core innovations, and it took several pivots to get to this architecture. When we started, we were exploring an analog-based approach, which had been researched for decades. The basic premise of in-memory compute is that you keep the model parameters in memory and perform matrix math computations directly in place. This is particularly efficient for AI inference workloads because they are fundamentally heavy on repetitive, parallel matrix math.
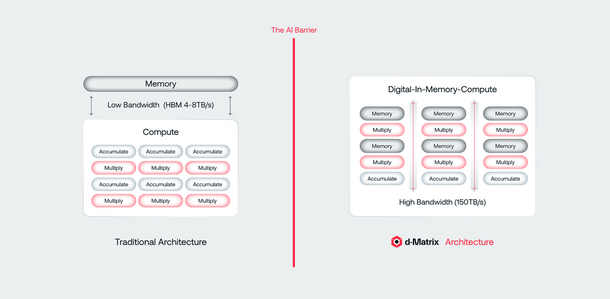
Initially, we looked into analog methods using exotic memories like flash or ReRAM, which are structured well for matrix math. However, customers—especially large hyperscale data centers—voiced concerns about the accuracy loss in analog computing. Inference workloads demand high precision, and analog methods simply couldn't meet their expectations. So, we pivoted to digital techniques.
Our first attempt was an SRAM-based memory architecture, where multiplication happened in the SRAM cells, and summation occurred in the analog domain. We built and demonstrated this to customers, but they were still concerned about the potential for accuracy loss due to the analog summation. Their feedback led us to develop the current all-digital in-memory compute architecture.
The key innovation is replacing the analog summation with fully digital adder trees. This approach allows all the rows in the memory array to be activated simultaneously, creating a data flow engine. Multiplication happens within each augmented bit cell, and the results are processed through the adder trees, all in the digital domain. This eliminates the need for analog-to-digital conversion, which often introduces inefficiencies and accuracy issues.
What makes this architecture groundbreaking is its ability to combine the accuracy and predictability of digital computing with the energy efficiency of in-memory compute. It’s a solution tailored to the needs of hyperscale data centers, and we believe it’s the first of its kind to achieve this balance at scale.
How does d-Matrix's DIMC engine perform in terms of power efficiency, speed, and throughput compared to competitors like Groq?
Our DIMC engine is fundamentally different from anything else out there, including what our peers like Groq offer. The architecture provides three primary benefits: latency reduction, energy efficiency, and throughput improvement.
Energy Efficiency:
The engine demonstrates a power efficiency ranging from 30–40 TOPS (Tera Operations Per Second) per watt to as high as 150 TOPS per watt in the lab. This range depends on the workload and operating conditions, but reaching 150 TOPS per watt is a standout metric in the industry.
Throughput:
Unlike traditional compute engines that fetch data one row at a time from SRAM, our DIMC engine activates all rows in the memory array simultaneously. For example, in a 64x64 array, all 64 rows are activated at once, leading to a dramatic boost in throughput—up to 60x improvement compared to conventional methods.
Latency:
By keeping model parameters in memory and performing computations directly in place, we achieve a 10x improvement in latency. This approach eliminates the need to move large amounts of data back and forth, which is a significant bottleneck in traditional architectures.
Overall, this combination of benefits makes our platform a leader in energy efficiency, speed, and throughput for generative AI inference. It’s not just incremental improvement—it’s a rethinking of how inference should be done.

Is d-Matrix primarily targeting cloud data centers, or are there plans to expand into edge computing and personal devices?
Yeah, so we’re launching in the cloud right now, and that’s where we’ll be for the foreseeable future. I’d say at least the next three years. But the way we’ve built the platform, there’s nothing stopping us from going into workstations or even client PCs down the road.
When we talk about edge, for us, that means going into high-end workstations for power users who want to run inference at their desk or even into client PCs for developers who need inference capability locally. So, yes, eventually, we do want to go into that space. And because we’ve built the platform with chiplets, we can scale it up for data centers or scale it down to fit inside workstations or client devices. We’ve already had interest from that segment, so it’s definitely on our radar.
Who do you see as your primary competitors in the AI inferencing space, and how does d-Matrix differentiate itself?
Hmm who do we perceive as competition? To be honest, the way we’ve built the platform is very unique, so we really don’t see anyone building it quite the way we are. That’s a big differentiator right there.
When we go into our target customers, we run into competition primarily because of our disaggregated hardware business model. Unlike some other players, we’re not in the business of hosting a cloud and selling tokens as a service. That’s just not us. We enable others who want to do that—whether they’re selling tokens or deploying applications and workloads. At the end of the day, we’re a traditional chip and hardware company.
What does that mean? We build chips, we design accelerator cards, and then we sell those accelerator cards to our target customers. From there, we work with ecosystem partners, like server vendors, to put together complete solutions, and we collaborate with end customers to deploy those solutions at a rack scale.
Because of this, our competition is mainly the traditional chip guys. Obviously, NVIDIA—you can’t talk about this space without mentioning them—they’re trying to do everything. Then you’ve got AMD, Intel, and even some Qualcomm. These are the folks we compete with most.
We do occasionally bump into our startup peers, but a lot of them are leaning more into the services side of things rather than the traditional hardware route. So it’s a slightly different approach from ours.
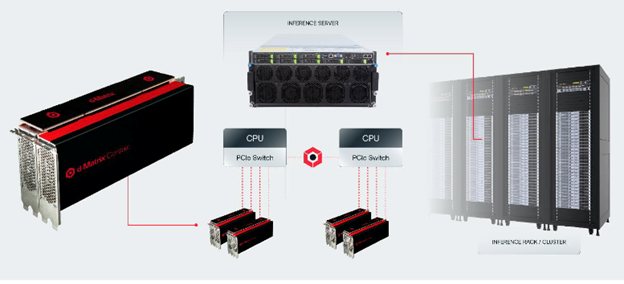
Corsair is available in an industry standard PCIe form factor and is easy to scale from a care to server to racks and integrate in existing AI rack infrastructure.
You’ve held significant roles before, seen companies through acquisitions, but now you’re leading d-Matrix as co-founder and CEO after a big Series B and rapid growth. What has that been like for you, personally?
The ride of my lifetime, for sure. Every day I wake up, and I’m like, wow, I couldn’t have planned this if I tried. Some of these things just happen—they’re serendipitous. But my philosophy has always been pretty simple: I wake up in the morning, and I want to do exciting stuff. That’s just how I live.
I don’t spend too much time thinking about where I’m going or planning years ahead. I don’t sit around crafting visions of where I want to be. Instead, I keep a high-level sense of direction—like, okay, this is the problem I want to solve, or this is the product I want to build, or this is the customer I want to make happy. I get a hunch about where that might lead over time, but I don’t dwell on it. I just focus on the work and enjoy the process.
That’s really been my philosophy from the start of my career. If I’m not having fun, I won’t do it. If I am, I’ll stick with it for as long as it keeps being fun. Every now and then, I stop, look back, and think, wow, look how far I’ve come just by following that mindset. It’s a simple way to live, and it works for me.
I want you to stretch your imagination to envision a world where AI is fully matured and embedded into society. From your perch as an AI chip founder, what does that world look like 10 or 20 years from now?
A lot of human beings hanging out at the beach, I would assume! But no, seriously, I think people naturally have this fear when it comes to AI—fear of being displaced, of losing relevance. And while I understand that, I think it’s the wrong way to look at it. These kinds of paradigm shifts have happened before and will keep happening. Personal computing, the internet, social media—they were all massive transitions, and each one was bigger than the last. But ultimately, they’ve taken humanity forward, not backward.
Looking 20 or 30 years out, when AI is pervasive and everywhere, I don’t believe it will “take over” in some dystopian sense. Of course, we need to approach it with care and a sense of responsibility, like we should with any powerful tool. But I’m confident humanity will rise to that challenge. If we hadn’t been careful with the many transformative things we’ve invented in the past 5,000–10,000 years, we wouldn’t even be here today.
When AI reaches its full potential, I think it will enhance humanity rather than replace it. It’ll be a copilot, a companion—a tool that helps us move faster, create more, and feel less isolated. Imagine always having a cognitive partner to help you through tough times or to make the creative process more enjoyable. That’s the future I see—one where people are liberated to focus on creative, meaningful pursuits and live fuller lives. Net-net, I think it’s a better world we’re heading toward.
Tell us about the team at d-Matrix. How big is it, and what kind of culture have you, as founder and CEO, tried to build into the company from your own personal experience?
The team at d-Matrix is incredibly resilient and experienced, and we’ve built it piece by piece with a lot of care. One of the core aspects of our culture, which I’ve tried to instill from the very top, is intellectual honesty. That means ideas can come from anywhere, and it’s absolutely okay to say, “I don’t know.” We prioritize having a learn-it-all mindset over a know-it-all mindset.
This mindset allows us to fail quickly. If we make a decision that doesn’t work out, we’re fine pivoting and moving in a different direction. We don’t let our egos get in the way—if the data tells us something we don’t like, we embrace it and adapt. That approach starts with me. I’m still working on being better at saying, “I don’t know,” but I remind myself it’s okay to let go, trust the data, and let that guide our decisions.
This culture also creates a safe space for the team to make mistakes. As long as they’re learning from those mistakes, it’s encouraged. To me, the most important part is what the team is learning and who they’re becoming as a result of that learning. Building a company is a process—it’s a collection of individuals growing and working on themselves. The more the team works on self-improvement, the better our chances of building something truly extraordinary. That’s the kind of environment we strive for at d-Matrix.
Conclusion
To stay up to date on the latest with d-Matrix, learn more about them here.
Read our past few Deep Dives below:
If you would like us to ‘Deep Dive’ a founder, team or product launch, please reply to this email ([email protected]) or DM us on Twitter or LinkedIn.