- Cerebral Valley
- Posts
- Our chat with Datastax's Chief Product Officer, Ed Anuff ❇️
Our chat with Datastax's Chief Product Officer, Ed Anuff ❇️
Plus: Ed on scaling critical AI applications within the enterprise...

CV Deep Dive
At Datastax, Ed oversees a product line that has evolved to meet the demands of modern AI-driven applications. This includes their cloud-based Astra DB, a serverless database, and recent innovations like vector support and Langflow 1.0, which simplifies building retrieval-augmented generation (RAG) applications for GenAI use cases. Datastax’s commitment to working hands-on with enterprises to move AI applications from pilot to full-scale production sets them apart in a competitive market.
Ed’s journey to Datastax began after a successful tenure at Google, following Google’s acquisition of his previous company, Apigee, which specialized in API management. With a deep background in both enterprise and internet startups, Ed joined Datastax about four and a half years ago. Datastax, founded in 2010, is renowned for commercializing the Apache Cassandra database, a powerful system originally developed at Facebook to handle massive data loads with horizontal scalability. Today, Cassandra is a critical component in the tech stacks of major companies like Apple, Netflix, and Home Depot.
Datastax raised $115 million in June 2022, led by Goldman Sachs with participation from Rokos Capital Management, OnePrime Capital, Meritech Capital Partners, EDBI, and Crosslink Capital.
In this conversation, Ed delves into the evolution of Datastax, the challenges of scaling AI applications in enterprises, and what sets Datastax apart in the competitive RAG space.
Let’s dive in ⚡️
Read time: 8 mins
Our Chat with Ed 💬
Ed - welcome to Cerebral Valley! Let’s start with some background on yourself and what led you to join Datastax?
Hey! I'm the Chief Product Officer at Datastax, having joined about four and a half years ago after spending four years at Google, where I landed after Google acquired my previous company, Apigee, which specialized in API management. I've worked at several startups over the years, both in enterprise and Internet spaces.
Datastax was founded in 2010 to commercialize the Apache Cassandra database, originally created at Facebook for their inbox search. Cassandra is built on the designs from Google and Amazon, focusing on creating a database that scales horizontally—meaning it can handle an unlimited amount of data by simply adding more servers. Today, Cassandra is used by major companies like Apple, Netflix, Home Depot, and many others. If you're dealing with a company handling massive data loads, there's a good chance they're using Datastax somewhere in their tech stack. Now, DataStax is leveraging the power and scale of Astra DB powered by Cassandra, alongside Langflow to deliver an AI PaaS that solves for all parts of the AI development lifecycle.

Could you break down the Datastax product line for us, including where you're currently using AI, and clarify how developers can use Langflow?
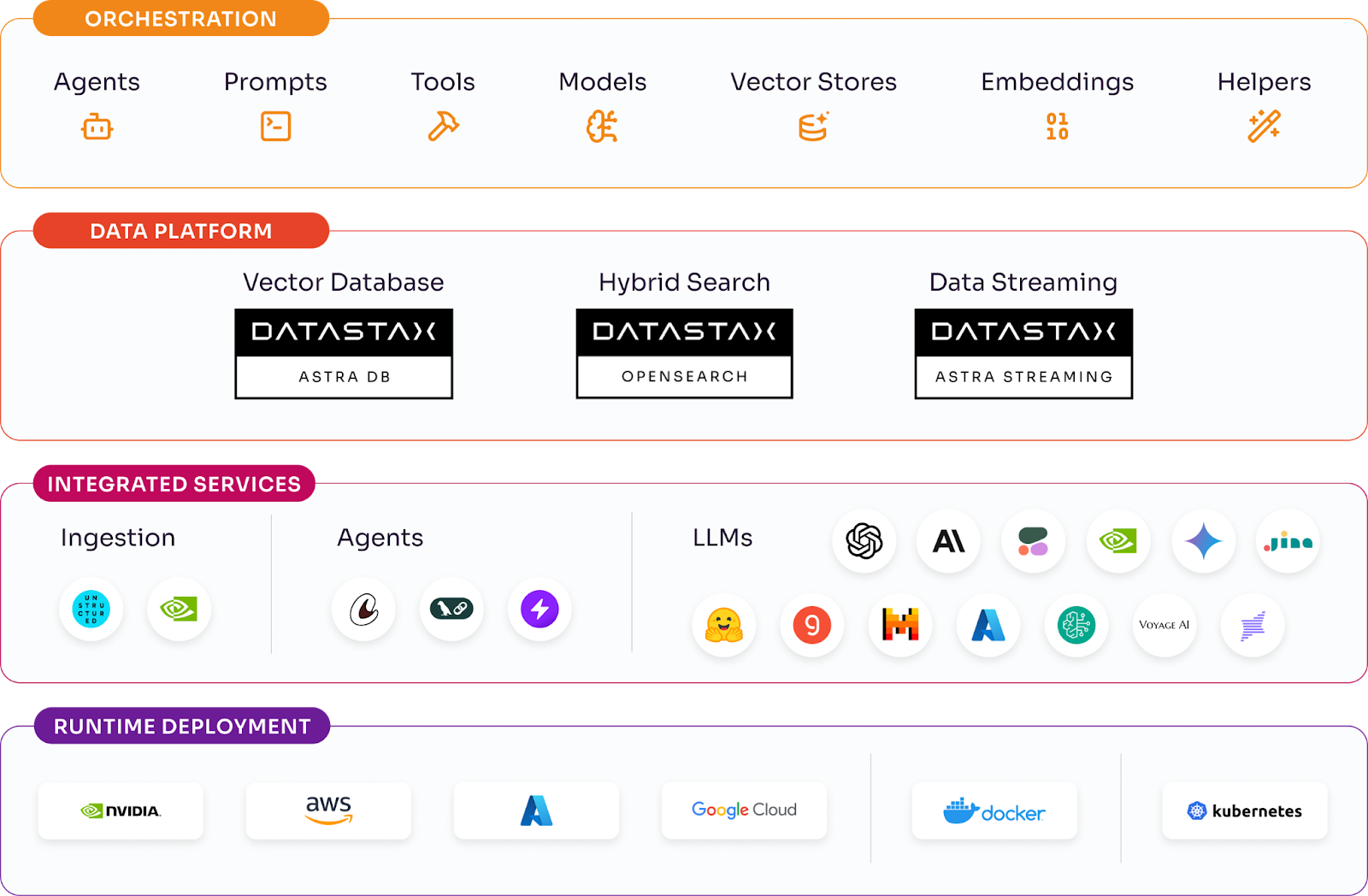
Sure. Datastax essentially has two main product lines. First, we have our enterprise products, including Datastax Enterprise and Hyper-Converged Database, which are versions of Cassandra that you can deploy yourself in your own data center or in the cloud. About four years ago, we introduced a cloud version called Astra DB, which is a serverless database that offers all the benefits of our enterprise software without the need for self-installation. It's scalable for any project, from side projects to large enterprise data needs.
A couple of years ago, we began focusing on machine learning use cases because when you're dealing with large data sets, the natural progression is to use that data for training models. We explored how to make that easier, especially with the rise of generative AI. This led to our work on vector databases, which we rolled out in late 2022 and fully launched last year. It's become a significant part of why people sign up for our platform—over half of our users are now engaged in some form of vector database or generative AI use case.
Our AI PaaS emerged as part of our effort to build on top of the database. As more businesses build GenAI applications, particularly retrieval-augmented generation (RAG) applications, they need to pull together various tools like LangChain and others. Our AI PaaS simplifies this process by bringing everything together in one place, making it easier for developers to start building these applications. With our AI PaaS, users can easily build RAG or agent applications through a drag-and-drop interface, and then run them in the cloud or export them for use elsewhere. This approach helps streamline the process of building applications on top of our database, particularly for AI and GenAI use cases.
It sounds like Datastax caters to enterprises as well as individual developers. Are there any specific customer success stories that stand out?
Absolutely. We've had several notable success stories. One that stands out is with Skypoint, which operates in healthcare. They've been using GenAI to automate communications between doctors, families, and caregivers. This is crucial because doctors are often very busy, and these automated systems help generate follow-up care documents and communications that are personalized. This works well in a RAG-based application, where you can safely retrieve electronic medical records and generate personalized content.
Unlike generic experiences like "chat with PDF," these personalized RAG applications can really wow users by making contextually relevant suggestions. It's all about assembling the right context with multiple retrievals and making the model work seamlessly. The results can be astonishing.
🎉🏆 Introducing our newest DataStax Digital Champion: @mathewtisson of @skypointcloud
Tisson discusses SkyPoint's reliance on real-time AI—and why vector search has become an integral part of the Generative AI stack. dtsx.io/44M1QJF
#GenerativeAI#VectorSearch
— DataStax (@DataStax)
4:00 PM • Jul 18, 2023
Some big names are competing in the enterprise RAG space. Can you help us understand the competitive landscape and what specifically sets Datastax apart from a developer's perspective?
Let's break this down by looking at enterprise requirements. Most pure-play startups in the database space will face challenges in the enterprise market. It’s not because they don’t have potential, but because it takes years to get enterprise solutions right. From experience, entering the enterprise market too soon can slow down a startup significantly.
Enterprise customers require a hybridized search capability—meaning their database must be fully performant and robust not just in retrieving vector data but also in query data modeling, operations, and management. Purely focusing on vector retrieval isn’t enough because there are too many established alternatives like Datastax, MongoDB, Elastic, Redis, DynamoDB, . Enterprises already using these robust systems are unlikely to switch to a new provider that doesn’t offer the same breadth of functionality.
When Datastax approaches an enterprise, they often find that the company may already be using Datastax, MongoDB, Elastic, and sometimes even Oracle’s latest offerings. The decision to use Datastax often hinges on whether the application is customer-facing, such as a chatbot interface for a major retailer that needs to scale efficiently. This is where Datastax's scalability and reliability become compelling.
However, it’s important to note that both large and small companies are currently experimenting with small-scale pilot projects. Many startups may claim to be selling to enterprises, but often they are only providing solutions for small departments or pilot deployments—not full-scale production systems. The real challenge in the database space, especially with consumption-based business models, is to get these GenAI apps into production. Our AI PaaS enables small scale pilot projects to get from concept, to experimentation, to production quickly. Without production workloads, a database company won’t see significant revenue. That’s the key battle right now—how to move from prototype and experimentation stages to full-scale production deployments.
Shared some of my thoughts on the accelerating pace of GenAI adoption and its ramifications for the tech industry.
Check it out:
#GenAI#TechInnovation#DataStax
— edanuff (@edanuff)
3:42 PM • Apr 8, 2024
So it’s the hand-on, collaborative implementation with the customer that sets Datastax apart?
Many of our customers come to us when they’re looking to put a GenAI app into real production, at scale. That’s really where we stand out.
Among the large enterprise database companies, I believe Datastax does the best job of rolling up our sleeves and truly working alongside the developers building these apps. Many database companies jumped on the GenAI bandwagon for the marketing buzz—they added a vector data type and claimed to be in the market. But the reality is, they haven’t built these apps themselves. They haven’t gone through the process of creating RAG applications or agents. They might have some blog posts written by consultants, but they haven’t actually walked the walk.
At Datastax, we spend a lot of time with our customers figuring out why a RAG app might not be working as expected, what needs to be adjusted in terms of chunking or embedding strategies, whether fine-tuned embeddings are necessary, and which models should be used. This isn’t a consulting service; it’s just how we work with our customers. It’s a lot of work, and ideally, we wouldn’t have to be this hands-on forever, but to credibly partner with companies in building AI apps, we need to show up and demonstrate that we know what we’re talking about.
When you work with Datastax, you get this deep, hands-on experience. You might get a similar level of AI expertise from some smaller players, but they often can’t prove they can handle large-scale operations or manage complex business relationships as effectively as we can. So, while we are as AI-native as anyone in this space, we can also handle the more challenging use cases at scale, which sets us apart. But this is something we have to earn every day.
We've rolled out two new integrations with @UnstructuredIO! ✌️👏
➡️ Astra Data Loader now supports PDFs
➡️ @langflow_ai has a new Unstructured component for flexible document ingestion
Get started with DataStax ➕ Unstructured:#AIApplications
— DataStax (@DataStax)
5:01 PM • Sep 4, 2024
How do you see Datastax progressing in the next six to twelve months?
Our primary focus is on helping customers get their RAG applications into production. These applications need to become more cost-effective, more relevant, and they need to get the right data integrated efficiently. One major area we're focusing on is improving data ingestion, which has become increasingly challenging as datasets grow larger. Additionally, as people start integrating industry-specific datasets, different querying algorithms like ColBERT and knowledge graphs are becoming crucial, and we’re actively exploring these areas.
Fine-tuning embeddings has also emerged as a significant area of focus. Six months ago, many model providers misguided enterprises by promoting model fine-tuning as an alternative to RAG, which didn’t pan out as expected. However, fine-tuning embedding models has proven to be highly effective, and there’s a need for more automated tooling around this, which we’re working on.
We’re also putting a lot of effort into enhancing Langflow, our visual LLM orchestration tool, which has seen a fantastic response from developers. Beyond its visual tooling, many developers use it to serve up APIs, and we’re planning to make it even easier to deploy these APIs in the cloud or on other providers.
Moreover, we’re closely collaborating with Nvidia. We’re embedding their NeMo microservices into our offerings, allowing users who sign up for Astra DB to automatically access free Nvidia embeddings, thanks to this partnership. These are some of the key areas we’re focusing on in the near term, and there’s more to come as we continue to push the boundaries of what our platform can do.
Astra AI PaaS gets retrieval embedding boost w/ NVIDIA NeMo Retriever! #Langflow & #AstraDB now come w/ NeMo Retriever by default for top GenAI apps.
Learn more:
— edanuff (@edanuff)
5:41 PM • Jul 23, 2024
You made an astute observation – we are shifting away from fine-tuning models in favor of leaning more on RAG and fine-tuned embedding models. Could you expand on why that shift is happening?
Absolutely. One major issue the model providers missed is that most enterprise data can’t be fully integrated into an LLM due to privacy concerns. You can train it into an embedding model, but not into an LLM, because anything fed into an LLM can potentially be retrieved. For instance, you can't safely integrate something like electronic medical records into an LLM, because the model could accidentally regurgitate sensitive information, like patient names, which is unacceptable.
This is why RAG-based systems are essential, especially for personalized systems where privacy is paramount. While fine-tuning is powerful, it doesn't eliminate the need for RAG systems. The model providers last year were pushing the idea that fine-tuning could replace RAG, but that’s simply not feasible. RAG, or whatever we end up calling it, remains necessary for retrieving knowledge from trusted sources at runtime.
Another important point is that while guardrails in AI can reduce risks, they don't eliminate them entirely. For instance, using guardrails might ensure that inappropriate answers occur only one in a hundred times instead of one in five, but when it comes to handling sensitive information, even a one-in-a-hundred mistake is too many. This is particularly critical in scenarios like personalized recommendations or e-commerce, where privacy breaches, even minor ones, can have serious repercussions. The goal is to avoid any situation where, for example, a personalized assistant mistakenly reveals another user's experience or preferences.
Curious about vector embeddings? 🤔
This latest Medium post breaks down what they are and their role in building GenAI apps.
Discover how these powerful tools can enhance AI capabilities and transform your projects. 🚀
— DataStax (@DataStax)
5:02 PM • Aug 16, 2024
Could you tell us a bit about the culture at Datastax, what you look for when hiring new team members, and any specific roles you're focusing on right now?
Datastax has been built as an open-source company from day one, which deeply influences our technical culture. We're all about openness, leveraging the best ideas no matter where they come from. Being an open-source company has also made us a fully distributed organization, allowing us to bring together a great team of people from all around the world, whether they’re in Brazil, Asia Pacific, Europe, or elsewhere. This global reach is something we’re really proud of, and it’s allowed us to work with top-tier talent without requiring them to relocate to Silicon Valley.
Another aspect of our culture is our focus on getting technology into production at a scale that few other companies can match. This was something I appreciated at Google, and it's a driving force at Datastax as well. We’ve also been quick to pivot and prioritize generative AI, recognizing early on the significance of the pace of change in this space. We made AI the most important focus for the company, especially in terms of helping people bring their data to their AI applications.
As for hiring, we're always looking for people who want to work deeply with data. Right now, we’re expanding our team significantly, especially around Langflow, our visual LLM orchestration tool. We’re doubling the size of that team, so if someone’s interested in front-end development, particularly in building web apps with Node or Python, or has experience in JavaScript, we’d love to talk to them. We're also adding data scientists and those interested in working on things like our graph implementation. There are a lot of exciting opportunities at Datastax right now, and we're keen to bring on more talent to help us push the boundaries of what's possible.
Conclusion
To stay up to date on the latest with Datastax, learn more about them here.
Read our past few Deep Dives below:
If you would like us to ‘Deep Dive’ a founder, team or product launch, please reply to this email ([email protected]) or DM us on Twitter or LinkedIn.