- Cerebral Valley
- Posts
- CTGT's Cyril Gorlla is Opening the “Black Box” for Enterprises
CTGT's Cyril Gorlla is Opening the “Black Box” for Enterprises
Plus: Cyril on the technical challenges they've overcome in the AI space...

CV Deep Dive
Today, we’re talking with Cyril Gorlla, Co-Founder and CEO of CTGT.
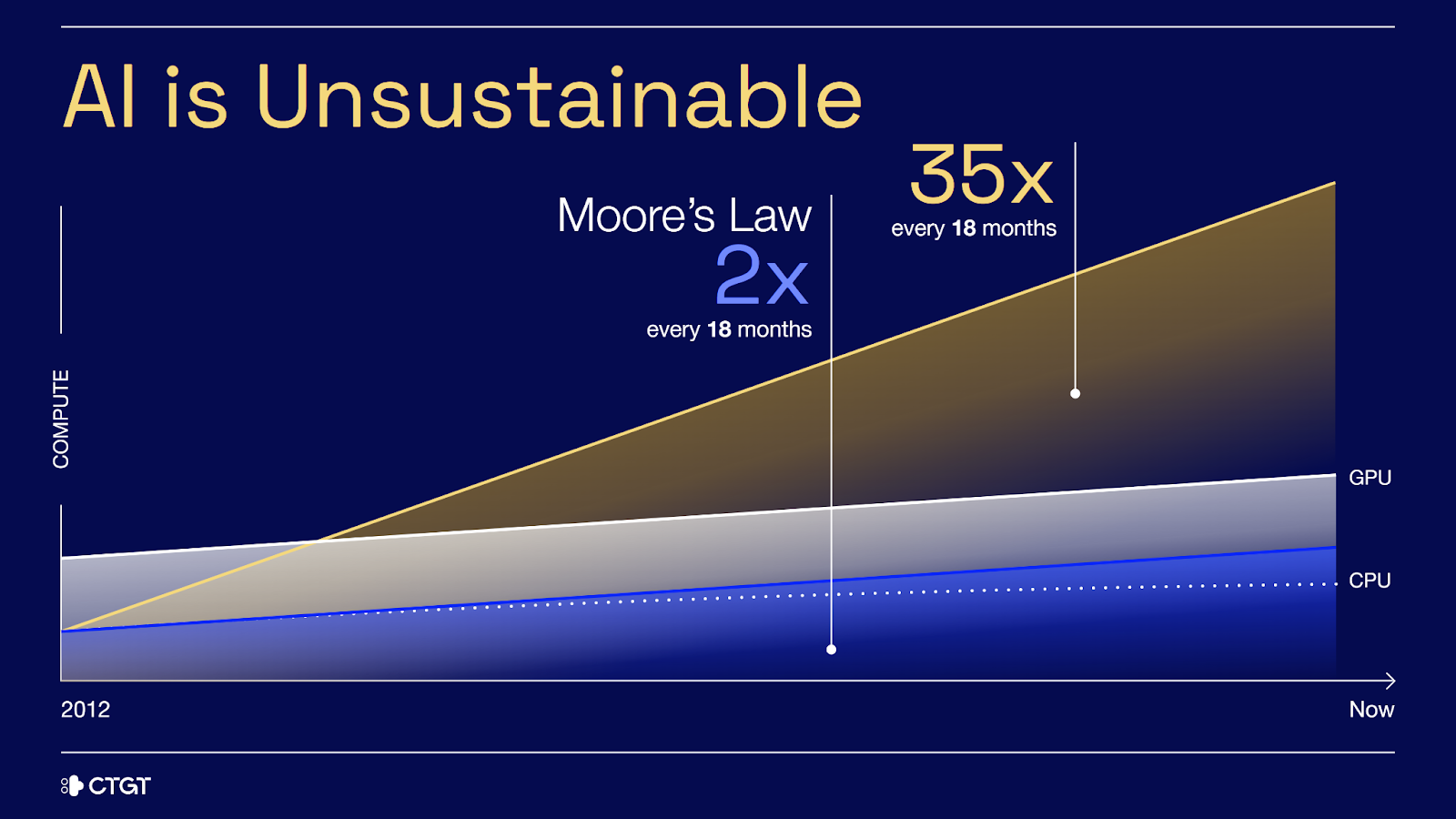
CTGT is revolutionizing AI by focusing on building more efficient, interpretable, and sustainable deep learning models. Rooted in research from UCSD, CTGT offers enterprises, including multiple Fortune 10 companies, the tools they need to deploy AI responsibly and at scale. By addressing critical issues like bias in models, hallucinations in large language models (LLMs), and reducing the need for excessive compute, CTGT empowers companies in sectors like healthcare and finance to trust and benefit from AI more effectively.
CTGT helps businesses move AI out of the demo phase and into production by improving AI's ROI and ensuring that it aligns with organizational strategies. Their platform reduces the barriers to deploying advanced AI, giving companies access to state-of-the-art models without requiring massive computational resources.
In this conversation, Cyril shares his inspiration for founding CTGT, the technical challenges they've overcome in the AI space, and what’s next as they continue to refine their solutions to make AI more accessible and impactful for businesses.
Let’s dive in ⚡️
Read time: 8 mins
Author: Daniyal Malik
Our Chat with Cyril 💬
Cyril - welcome to Cerebral Valley! First off, give us a bit about your background and what led you to found CTGT?
I'm the co-founder and CEO of CTGT. My background, ever since I was young, was marked by a love of technology. I come from an immigrant family, and I saw the power that technology has to change people's lives, both in good and bad ways—whether it's through algorithmic bias in loan decisions or giving people access to learning and opportunities they wouldn’t have had otherwise.
I actually taught myself to code when I was eleven. I even took my mom’s college programming course, and I aced it, which really got me into programming at a young age. Later, when I became more aware of the world and the problems out there, I got exposed to AI and machine learning in high school. It was very nascent back then—not so much scientifically, but in the public space. Google had just started implementing what we would now term AI in their systems. I remember watching Google I/O in 2014, and seeing them debut the first inklings of now-ubiquitous features like predictive analytics in Android Auto.
At that point, I didn’t have the resources to do AI in any significant way, but I learned that compute was a big hurdle. So, when I was 14 or 15, I started opening up my laptops and replacing the thermal paste to get a little more performance out of them, just so I could run models.

At 17, I got a full ride to UCSD, which has one of the top computer science departments in the U.S. and the world. While there, I was part of the first undergraduate cohort at the Halıcıoğlu Data Science Institute, founded by Taner Halıcıoğlu, Facebook’s first full-time employee. My undergrad work focused on practical applications—one of the projects I worked on with Intel was machine learning in a telemetry framework deployed on over 8 million CPUs. I also did some cybersecurity work after a data breach at UC. Using machine learning, I was able to identify those affected and notify them months before the official UC response.
For these efforts, I was named one of the twelve shining stars of UCSD’s class of 2022 out of over 12,000 graduates. After that, I moved on to grad school as part of the first cohort of UCSD's data science graduate program, where I worked with Misha Belkin, an ACM fellow. My research operated on a heterodox conviction in deep learning—throwing more compute at problems wasn’t going to lead to true intelligence. We needed to think more intelligently about how to solve learning problems sustainably.
In Misha’s lab, I worked on the efficient training of large-scale models and my work was invited to ICLR in my first year of grad school. That research really became the driving force behind starting the company.
New @iclr_conf#ICLR2023! Looking forward to presenting this work on the training dynamics of kernel models with EigenPro 3 and recursive feature machines (RFMs). As such models become larger, we also need be able to understand their training better. openreview.net/forum?id=8WiND…
— Cyril Gorlla (@CyrilGorlla)
9:17 PM • Apr 27, 2023
Give us a top level overview of CTGT - how would you describe the startup to those who are maybe less familiar with you?
CTGT is grounded in the belief that deep learning, as it's being done now, is unsustainable. My co-founder, Trevor, and I wanted to address this issue. We wanted to find more efficient, interpretable ways of working with AI and make it more sustainable.
From my research, we already had companies interested in deploying more efficient AI solutions, and it’s been pretty surreal seeing code that originated in the academic space now running on Fortune 10 company servers. What we provide is a platform for companies to really understand their AI systems, mitigate issues like hallucinations in advanced models like LLMs, and train models more efficiently using our tech.

In an LLM response about food, our technology identifies that “glue” is a hallucination
Our goal is to move AI from tech demos to real-world, production-ready deployments, especially in critical industries like finance and healthcare. We help companies feel confident in deploying AI systems that generate real value and align with their AI strategies.
Talk to us about your users today - who’s finding the most value in what you’re building with CTGT?
We're seeing significant interest from large-scale enterprises, as they have the most to gain or lose from deploying AI. Right now, we're working with three Fortune 10 companies, and the results have been really promising. For example, in one case study, we helped remove bias from a facial recognition algorithm. Our technology was able to identify where the bias stemmed from—like in the hair and clothing—and allowed the practitioner to remove it in just one step.
We're also working with a leading provider of authentication, helping them deploy LLMs for fraud detection. Our system identifies where misclassifications are happening, which is a critical feature that current technologies can't effectively offer. It's especially useful in situations where models misidentify fraudulent behavior, and pinpointing where that error comes from is essential to refining the system.
One key challenge is the excessive compute required by approaches like monosemanticity, which attempts to find individual features in LLMs. They need hundreds of models to approximate a feature, which ends up demanding more compute than training the original model to find all the features. This issue ties into my overall view: to ensure AI can truly be transformative, it needs to be more efficient, sustainable, and accessible. This is where our solution is providing the most value right now.
How do you measure the impact that CTGT is having on AI as a whole?
To dive deeper into our core ethos, I believe there's a fundamental issue in how we're approaching AI development. As I mentioned earlier, we're kind of stumbling around in the dark, trying different things until something works, like transformers or diffusion models. Once those methods are deployed, we find ourselves scrambling to develop theoretical frameworks after the fact—trying to explain why something works or doesn't, and addressing problems like hallucinations well after these models are already in widespread use.
This isn't how other fields of science operate. Take electromagnetism, for example. Its practice is grounded in well-established principles, like Maxwell's equations. This principles-first approach is something I want to bring back to AI, where deep learning has dominated for the past decade. That dominance has led to a homogenization of the field, where everyone is focused on the same method—deep learning—at the expense of exploring alternative approaches.
Even current interpretability methods like monosemanticity, LIME, or SHAP are essentially just approximations. They rely on training hundreds of proxy models to better understand a primary model’s behavior. Our approach, however, looks at the problem from the ground up.
A typical machine learning problem differentiating between two classes, for example, a cat and a dog, represented by a red and blue circle. A traditional deep learning model tries to separate these two shapes, but the process is inefficient and will take a while. CTGT’s technology looks at the problem from a novel perspective where it's much easier to separate the two, learning the same quality of concepts as traditional AI with an order of magnitude or more better performance.
We focus on understanding how neural networks actually learn, enabling us to gain insights into complex models like transformers without needing to build these extra approximations.
There’s been an explosion of interest in domain specific, specialized AI. How has that shaped the way you’re thinking about building CTGT?
At CTGT, we’ve been paying close attention to the shift we're seeing across many industries, particularly in sectors like healthcare and finance. There’s a growing demand for domain-specific, customized models rather than the massive, generalized models we've seen in the past. Our technology is designed to meet that need. Right now, we can train machine learning and deep learning models 10x faster with 10x less compute. But with the next version of our platform, we’re aiming to allow users to train those same models with up to 500x less compute, all while maintaining or even improving accuracy.
This makes a huge difference for companies that don’t have access to massive GPU clusters. Currently, they might not be able to build models tailored specifically to their needs—like models for credit scoring or medical billing. Our perspective is that companies shouldn't be excluded from accessing state-of-the-art AI performance just because they lack those resources. AI is going to be the foundation for the next wave of technological advancements, and we want to ensure that more companies can leverage it for their specific use cases.
This trend towards smaller, more specialized models fits well with the solutions we’re building, and we’re excited to be part of that shift.
How do you plan on CTGT progressing over the next 6-12 months? Anything specific on your roadmap that new or existing customers should be excited for?
We've seen a consistent pattern with our customers. They'll start by testing out the interpretability features of our platform, putting one of their own language models through it, and when they see the results, they immediately want to know if they can train models from scratch using our approach. So, we're working quickly to scale our method to handle the largest workloads enterprises are running today.
Over the past year, we've made some significant progress—growing from handling tens of thousands of data points to billions, a leap that took deep neural networks about a decade to achieve. This growth speaks to the power of our principles-first approach.
It’s been an exciting few months for us. We won the Startup Showcase at the PyTorch Conference and were chosen for TechCrunch’s Startup Battlefield Top 20. We also secured a spot in Y Combinator's Fall 2024 batch, which had around a 0.5% acceptance rate—the toughest it’s ever been.
Excited to share what I've been working on the past few months! Thanks for the excellent reporting @Kyle_L_Wiggers
— Cyril Gorlla (@CyrilGorlla)
6:11 PM • Oct 29, 2024
These milestones show that we're addressing a critical technical challenge, providing real value to enterprises by moving from AI demos to deployments that create tangible results. Our goal now is to scale and bring this product to as many enterprises as possible, helping them realize the full potential of their AI strategies.
Lastly, tell us a little bit about the day-to-day at YC and the culture at CTGT. What do you look for in prospective team members that are joining?
Our YC experience has been incredible, especially getting to meet and learn from the pioneers of the technologies we use today. It’s been enlightening to see how much interest there is in deploying advanced AI models, but at the same time, it’s become clear that there’s a significant gap between the excitement around AI and what companies are actually able to implement. This gap is especially pronounced in industries with high regulatory oversight, where the risk tolerance for deploying AI is understandably low.
These companies often have access to powerful models, but they can’t trust the technology enough to use it fully for customer-facing applications. Whether it’s because of concerns over hallucinations or the lengthy iteration times required to get models ready for production, there’s still a lot of work to be done to bridge the gap between AI demos and real-world applications. We’re also seeing a broader trend toward more personalized AI—companies want models that reflect their brand and voice.
Our team comes from a very niche academic community, and it’s exciting to see the evolution of AI from where we were decades ago. It’s especially meaningful that our work is emerging from UCSD, where backpropagation, the foundation of deep learning, was popularized. We believe we’re at the forefront of a new learning paradigm, one that’s safer, more interpretable, and ultimately better than deep learning for AGI. Our team shares that vision and conviction that deep learning isn’t the final answer to AGI.
Anything else you’d like people to know about the work you’re doing at CTGT?
I think it's important for people to understand that what we're doing at CTGT isn’t just about technical research or foundational AI work—it’s deeply personal to me. From the moment I knew what a computer was, I’ve been driven by a desire to ensure that technology is used as a force for good, rather than something destructive. While we work at the cutting edge of AI learning methods, identifying what drives learning in neural networks, it's about more than just the tech. It’s about making sure AI is developed in a way that benefits humanity.
We’re at a critical juncture, uncannily akin to the period preceding the Manhattan Project, where we need to carefully consider how we're approaching AI and AGI. Are we just going to keep throwing massive amounts of compute at these models, hoping that a large enough training run will create superintelligence? Or should we approach this in a more thoughtful, measured way—one that’s grounded in solid theory and built on values that aim to do the most good for the most people? That philosophy, which has driven me from the early days of tinkering with laptops for better performance, is the bedrock of everything we do at CTGT.
Conclusion
To stay up to date on the latest with CTGT, learn more about them here.
Read our past few Deep Dives below:
If you would like us to ‘Deep Dive’ a founder, team or product launch, please reply to this email ([email protected]) or DM us on Twitter or LinkedIn.