- Cerebral Valley
- Posts
- OctoAI is flying the flag for autonomous AI 💡
OctoAI is flying the flag for autonomous AI 💡
Plus: CEO Luis on OctoStack, Octo's new deployment solution...

CV Deep Dive
OctoAI is a full-stack inference platform purpose-built for generative AI. Founded in 2019 by Luis as a spinoff from the University of Washington - where Luis is a Professor of Computer Science - the startup’s goal is to help startups and enterprises build reliable AI applications into production whilst abstracting away the underlying infrastructure needs around compute,models, and customization.
Today, OctoAI has hundreds of companies using its platform for accessing proprietary and open-source models, including at companies like Hyperwrite, Motherduck, Capitol AI and more. In 2023, the startup rebranded from OctoML to OctoAI, and a few weeks ago announced OctoStack, its new end-to-end solution for deploying generative AI models in a company’s private cloud.
In this conversation, Luis walks us through the founding premise of OctoAI, the concept of ‘autonomous AI’, and how OctoStack is the next phase of Octo’s growth within generative AI.
Let’s dive in ⚡️
Read time: 8 mins
Our Chat with Luis 💬
Luis - welcome to Cerebral Valley. First off, give us a bit about your background and what led you to start OctoAI?
Hey there! Quick background: I grew up in Brazil and came to the US almost 25 years ago to join IBM Research. At IBM, I was part of the Blue Gene team - where we built a big supercomputer focused on life science applications like protein folding. That's when I really got started as a computer systems architect, and there I built hardware for high performance factor processing, compilers, interconnection networks and so on. I subsequently did my PhD in parallel programming at the University of Urbana-Champaign, before joining the University of Washington as faculty 17 years ago.
The majority of my intellectual life has been exploring ways of building better, faster, more efficient and easily-programmable computers. Computer systems is about focusing on applications that have impact, and AI has been an area I’ve focused on for a good chunk of my life. At UW, we built some of the early machine learning compilers that became todays’ Apache TVM project, which is deployed at a large scale and runs on billions of machines today. That was the first time that I experienced one unified infrastructure built for getting a machine learning model to be high-performance and portable across a broad range of devices.
Fast forward to four years ago - the key PhD students in the project were graduating, and I had already been a professor for a while. I had already built a company in the past, and so that moment felt like the right opportunity to bring this technology to a broader audience. That’s what led to the founding of OctoAI.
Tell us about the evolution of OctoAI - how would you describe the original mission of the company, through to your position in the AI stack today?
The core focus of OctoAI’s founding team has always been around building better and faster computer systems with a focus on AI. Today, AI components like computer vision and biometrics-based authentication are everywhere you look, and at OctoAI, we’ve built a lot of the core pieces of the open-source ecosystem of AI software infrastructure, giving us a lot of visibility into the pain points of making system infrastructure scale to build AI applications.
Fast forward to today, making the most out of the infrastructure is necessary to make GenAI viable at a meaningful scale. With OctoAI, we’ve built a complete stack to serve GenAI in a way that is efficient, customizable and reliable for production applications. We have market-leading offerings across all of the major open-source models, as well as some commercial models that we serve on the platform, and these are all API-optimized from the network request down to the code generation. We abstract complexity - depending on what you want to do, we automatically balance speed and cost, making it very easy for folks to build applications.
A couple of things that are unique about OctoAI is that we allow customers to bring their own custom models, and we serve them for you. We’re also rolling out OctoStack, our private deployment option, where you no longer have to buy the compute from us and have full control of the deployment environment. A lot of customers want to have full control of their deployments - they don't want to expose their data, but they want to use the functionalities of our OctoStack. These are the key components of our AI system that you can instantiate and deploy, using your own compute infrastructure too.
AI autonomy is a concept that Octo has spearheaded in many of your blog posts and technical writing. Explain to us what AI autonomy means in the context of OctoAI.
At the highest level, autonomous AI is about making AI work for you. This essentially means enabling businesses to make the most out of AI innovation in a way that they control, and using the latest model that makes the most sense for them. It also means not giving up control of your data and making sure that your data serves you and not others - so using your own infrastructure in a way that you control.
In the context of OctoAI, AI autonomy is also about how businesses are able to use their compute, data, and the models that work for them, and not have to build the infrastructure to do so. This is what we offer them.
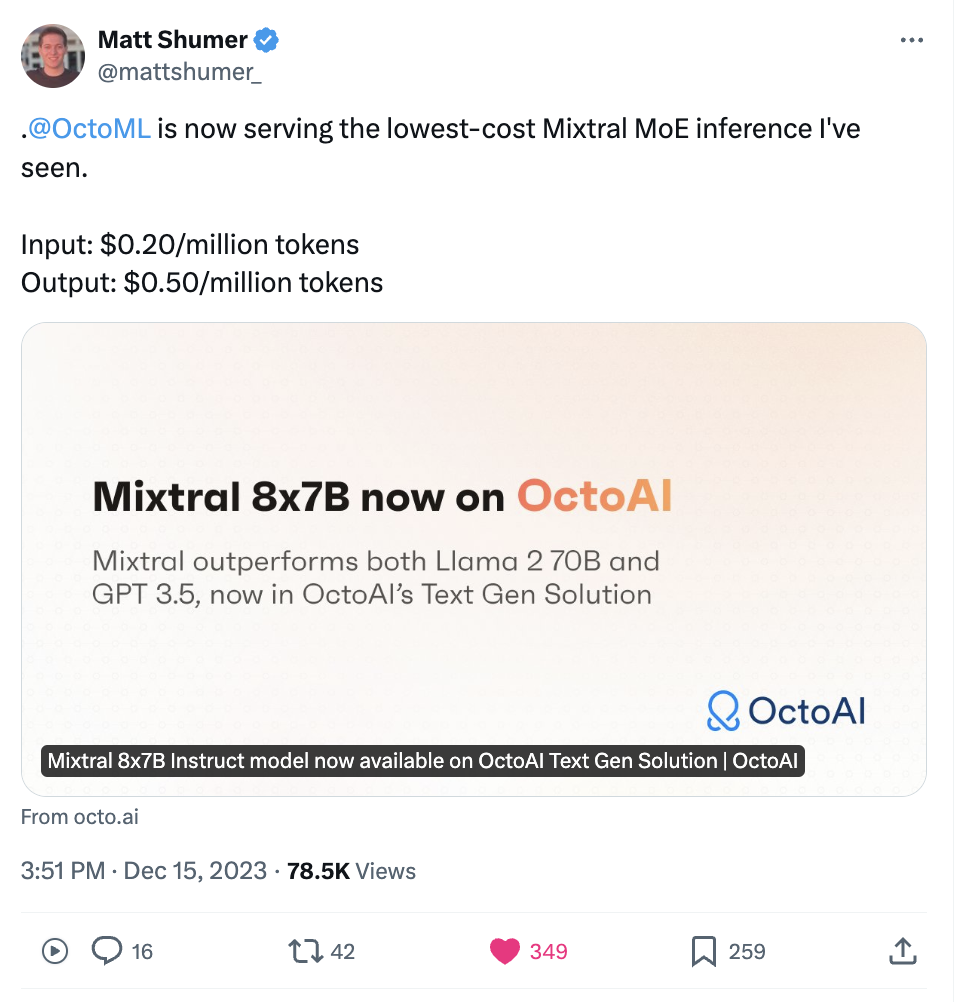
Given that you founded OctoAI in 2019, how did the advent of generative AI shape your trajectory, including the branding change from OctoML to OctoAI?
The key thing is understanding our history - over the years, our team built a lot of open-source AI software infrastructure; for example, Apache TVM, XGBoost, and more recently MLC LLM, which allows you to run models on phones and browsers, in addition to servers. Our first commercial product - back when OctoAI was called OctoML - was a tool around model optimization and packaging that converts a model into a highly optimized package. That was very general for any kind of model on any kind of hardware, and it was very much an MLOps tool - part of the process of deploying models.
Over time, it became clear to us that, because of Gen AI being so hardware-sensitive and performance-sensitive, we wanted to offer a more complete solution that allowed folks to access us via an API call. The previous product was very powerful, and we still use that core technology - however, our audience back then was machine learning engineers. Today, the key audience is general application developers, as GenAI has reached a level of maturity now that folks know what they want to do with it and how they want to integrate it into their applications.
As a result, our audience moved from an ML engineer to a general developer that knows how to call an API, but doesn't need to know the details of how to run a model, or even which model to use. Since we went from being a tool to help you deploy AI models, to being a platform for building AI applications, OctoAI felt like the right name to reflect the breadth and the scope of the problems that we’re solving.
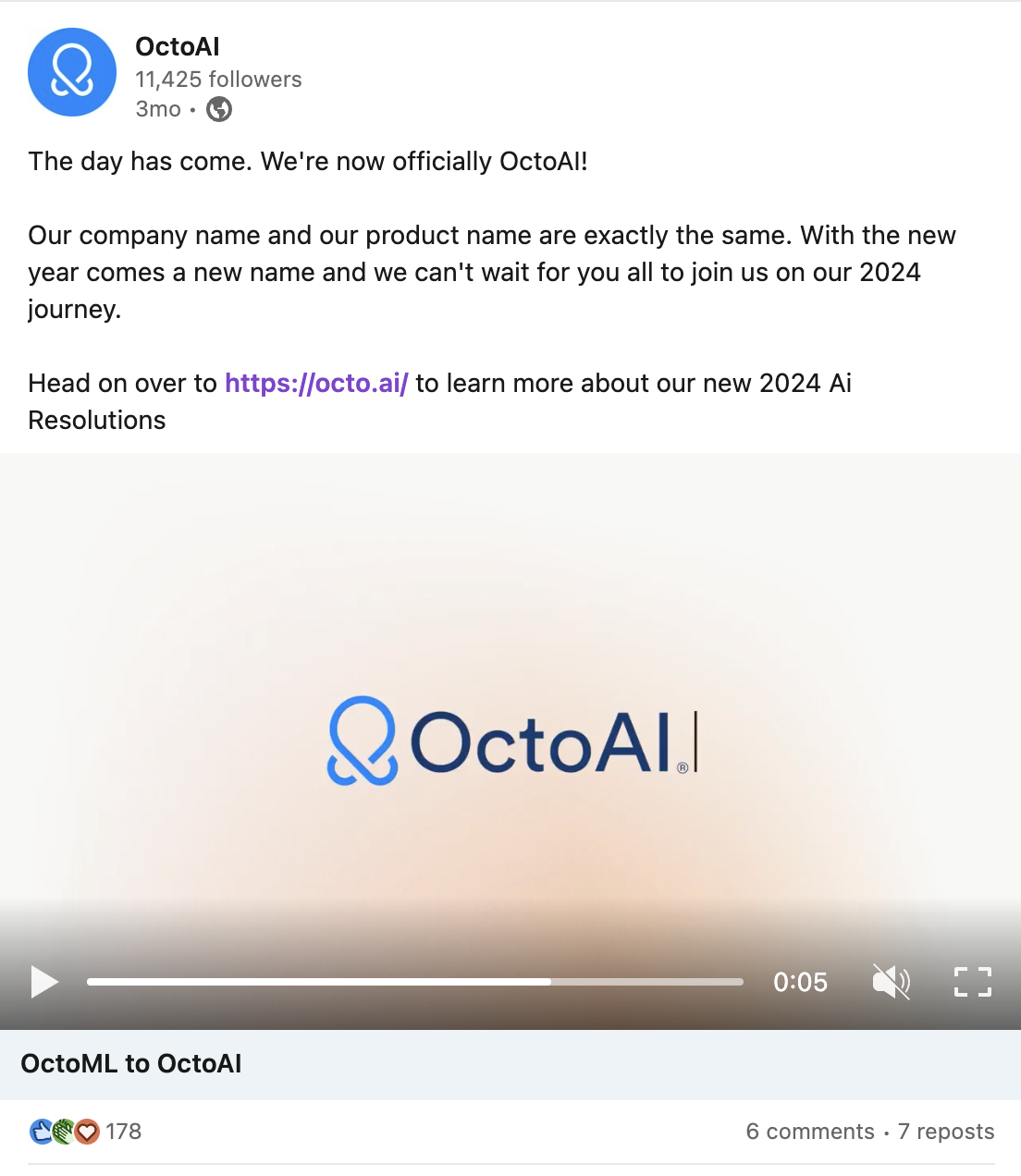
Walk us through some of Octo's customers - who are the developers or companies that are finding the most value in the platform today?
We have a very diverse set of customers in many segments, and our primary customers have very meaningful AI deployments today. We work with a lot of typical enterprises, but the majority of our business today comes from companies where GenAI makes up a significant portion of their business - meaning, AI-native companies. Some of the ones we talk about publicly are Night Cafe, Capital AI, Hyperwrite, Latitude IO and Motherduck, for example.
We do have a couple of other large enterprises whose names we can’t mention, and aside from them, we have companies across dev-tools, marketing software, education, e-commerce, productivity, document-processing, healthcare, robotics and so on. There's a huge range of companies that use our technology - all the way from AI native companies to larger enterprises.
Given the pace of AI breakthroughs, how do you balance the need for keeping up with AI research with the need to stay product-focussed internally?
Firstly, a good chunk of what we do is help our customers access the benefits of all of these AI innovations, both within the model layer as well as the systems layer. For example, there's a new attention mechanism or a new way of running LLMs better almost every other week! Part of our mission is to bring that to customers in a transparent way, enabling them to ride those innovations without having to do anything additional within their own AI stack.
Internally, we also help push the state of the art in AI systems - we have three MLSys papers coming up this year, for example, and that means that we know where the research questions are, as well as where the state of the art and the frontier of AI systems are, and we help push the boundaries there. In terms of balancing, we stay very focused on our customers, so we know what they need and what the technology trends are, and we can push some of these things to product sooner.
For example, we saw early on that there was this huge trend towards using parameter-efficient tuning LoRAs to customize models. We saw this in the context of Mediagen, where folks have visual identity that they build with LoRAs, and one of our customers had a large number of them. We decided to go and build a system that allows our customers to serve a bunch of customized models together very efficiently using the same infrastructure. We put that into the product right away because we knew that would have an impact.
Talk to us about the technical challenges around providing an inference engine for enterprise AI customers.
We've been betting on inference being the problem that's most worth solving commercially since the very beginning of the company. We’ve never had a training-focussed product - even before genAI, I had the point of view that companies would train a model and then try to deploy it as efficiently as possible across a broad range of devices. For any highly-valuable model that adds to people’s lives, you're going to spend the majority of the compute cycles devoted to that model towards inference rather than training.
This is especially true in GenAI because GenAI is going into production - so, there are a number of technical challenges between inference vs. training. First of all, training takes place in batch and inference is primarily online, meaning that there’s a request that comes in from a human on who’s giving the input. Now, there's a human at the other end waiting for the response back, which means that you want to have very high reliability on a per-request basis - because a dropped request is an unhappy user at the other end. We know that the reliability of every request is really important, and so we have market leading reliability - one of our customers has five ‘nines’ of reliability.
The other challenge is that the compute required is slightly different. With inferencing, you can do some batching to increase efficiency and group requests together. But, if you have to batch too much, then you’ll increase latency. So, you have to balance efficiency, throughput and latency - and it’s challenging to know which to optimize for every time.
Lastly, you want to be very mindful of how you balance speed and cost. The way to think about this is - what does the application actually need? Do you care about time-to-first-token, or time of completion of full request, or inferencing a large collection of inputs because you're going to do a higher-level summarization? Once you have that, then you can optimize the system for those parameters. With training, you have a ton of data and a well-defined training flow that you can checkpoint, so what you care about is what it takes for you to complete the whole training run. In inferencing, it's all about having manageable unit-economics and the right reliability properties.
What are the key areas of focus for OctoAI over the next 6-12 months?
The key priorities here are, firstly, getting OctoStack on the hands of users, our private deployment offering.
Secondly, we are diligently working on this idea of making sure that customers stay future-proof with respect to models and AI systems, essentially raising the level of abstraction around specific choices of model premise that customers have and making that automatic. So, the priority here is these two things around private deployment, as well as offering future proofing value to our customers.
Lastly, how would you describe your team culture? Are you hiring, and what do you look for in prospective team members?
First of all, we are a University of Washington spinoff, and the Computer Science department that we came from has a world-renowned culture of being very collaborative, creative and welcoming. Ours is a very collaborative environment - we win together and we go through challenges together. We also look for extreme technical excellence - we are surrounded by folks that help build a lot of the foundational pieces of AI infrastructure, and several of our folks at grad school have done research and now are focused on bringing their research to impact. So, there is a lot of bringing the state of the art to the broader masses here, done in a very collaborative way.
We also have very open and respectful communication here - we talk about hard problems openly, both technical and otherwise, and this is something that we value people's opinion on from around the company. Balancing inclusivity with making right decisions in order to make fast progress is part of our culture, too.
Finally, the only thing that's important is that we're here to actually make our customers successful. We all have a clear notion of mission here, and our goal is to build a fantastic product that's going to make our customers successful and embed everything that we know about technology and AI systems to make those products be awesome.
Conclusion
Read our past few Deep Dives below:
If you would like us to ‘Deep Dive’ a founder, team or product launch, please reply to this email ([email protected]) or DM us on Twitter or LinkedIn.