
CV Deep Dive
Today we’re talking to Shriyash Upadhyay and Etan Ginsberg, the founders of Martian.
Martian is a startup whose mission is to build a more interpretable alternative to the transformer. They started tackling this problem by inventing the model router, which they describe as a “Google for LLMs”. In a world with many websites, they say, the most important tool is one which can search through them all to give you the best result – the same is true of a world with many LLMs.
Martian released the first public model router in March 2023, hot on the heels of GPT-4, and their approach has professors and researchers dropping out of academia to join them.
Since then, Martian has raised $9M from NEA and General Catalyst, and are being used by developers at 300+ companies, from Amazon to Zapier.
In this conversation, we’ll dive into why Yash and Etan started Martian, the results they’ve helped companies achieve with routing, and practical aspects of the long-term future of AI.
Let’s dive in ⚡️
Read time: 8 mins
Our Chat with Yash and Etan 💬
Yash and Etan - welcome to Cerebral Valley. I’d like to start by asking about your company's mission. You shared a story earlier that I think our readers would find interesting.
Late last year, I gave a talk at the University of Pennsylvania on the work we're doing at Martian. At the end of the talk, one of the researchers there, Ben, came up to me. He said to me, “This is the most important problem anyone can possibly work on, and I’m willing to do whatever it takes to join you guys”. Then he dropped out of his PhD to join us.
When speaking to researchers and engineers, his perspective has not been anomalous. Engineers from top AI companies like Google and Microsoft have left to join us because the work we're doing is more fundamentally interesting. Professors, including at Ivy League universities, have offered to drop out of academia to join us.
What makes working on Martian so compelling? Why is understanding models something people should care about?
A problem is valuable if working on it has high value above replacement. Doing something people don't need is obviously not valuable (this is why the YC motto is "make something people want"). Less intuitively, starting a hotdog stand solves an important problem — hunger — but even though people want it, someone else will probably do it if you don't, and it therefore isn't very valuable.
Martian is solving a problem that we think is hugely important, and that nobody else will solve effectively otherwise.
Depending on who you ask in Silicon Valley, one of two things might be the most important problem of our time:
AI is going to kill everyone, OR
AI is necessary to solve humanity's most pressing problems, and fear of (1) will derail that
Understanding what these models are doing internally solves both of these problems.
If these models aren't safe, then understanding how they work is crucial to be able to align them and to create guarantees of their safety. And if they are safe, then such guarantees can eliminate the fear of AI models which comes from the fact that models are poorly understood. We can go from being indefinite pessimists (“the world is going to end, dunno how”) or indefinite optimists (“everything will be alright, dunno how”) to being definite optimists (“here’s how we can make the future safe”).
But, beyond the safety angle, we think this could be one of the biggest scientific breakthroughs of all time. Throughout history, the biggest advances have come from unifying disparate experimental results into a cohesive theory and understanding - like the shift from alchemy to chemistry. We want to do the same for AI, turning it from a field of black-box tinkering into a rigorous science. Martian's core business of model routing both enables and is enabled by this.
Unfortunately, the incentives at the big AI companies are fundamentally misaligned with doing the interpretability research needed to make AI safe and well-understood. Companies are incentivized to put most of their resources towards research that improves their core product. The largest AI companies today sell AI capabilities — therefore they fund research which makes their models more capable (i.e. more compute, more data, etc.) This is why, when these companies raise billions of dollars, most of it goes towards training new models and not doing interpretability research. Without Martian, nobody else is going to do this.
At Martian, we're building a company whose core product gets better the more you understand models: model routing.
What is model routing? How would you describe Martian to a researcher or developer that’s new to the product?
You can think of us like Google for AI models - every time you send us a request, we automatically find and use the model that will give you the best result at the lowest cost. Of course, while Google is a consumer product, we're an API used by companies.
This is the problem of model routing: how do we send each request to the best model?
Developers at over 300 companies, from Amazon to Zapier, use our software to route prompts this way. They see higher performance, lower costs, and greater security and reliability than using any single model provider.
The key is that by leveraging many models and routing between them dynamically, you can outperform any individual model, even ones like GPT-4.
We also abstract away the difficulty and expense of vetting, using, and upgrading all these different models. Developers just tell us what they're trying to do and their cost/latency requirements - we ensure they always get top performance.
This gets to the heart of why routing solves the incentive problem. To do routing effectively, you need to deeply understand the models you're routing between. You have to be able to predict their performance on a given task without running them.
So, our success is directly tied to our understanding of models. The better we understand them, the better we can route. This creates a clear incentive to do more interpretability research, in contrast with model providers.
How does routing lead to higher performance than individual models?
There is a common misconception companies have, that they can evaluate the most common models, find the “best” model for their use case, then simply use that single model. This is especially true of use cases that appear to be quite specialized. The problem is, even in the most niche use cases, there is a sufficient variance across models that by routing between models, you can arbitrage their differences and get a better result.
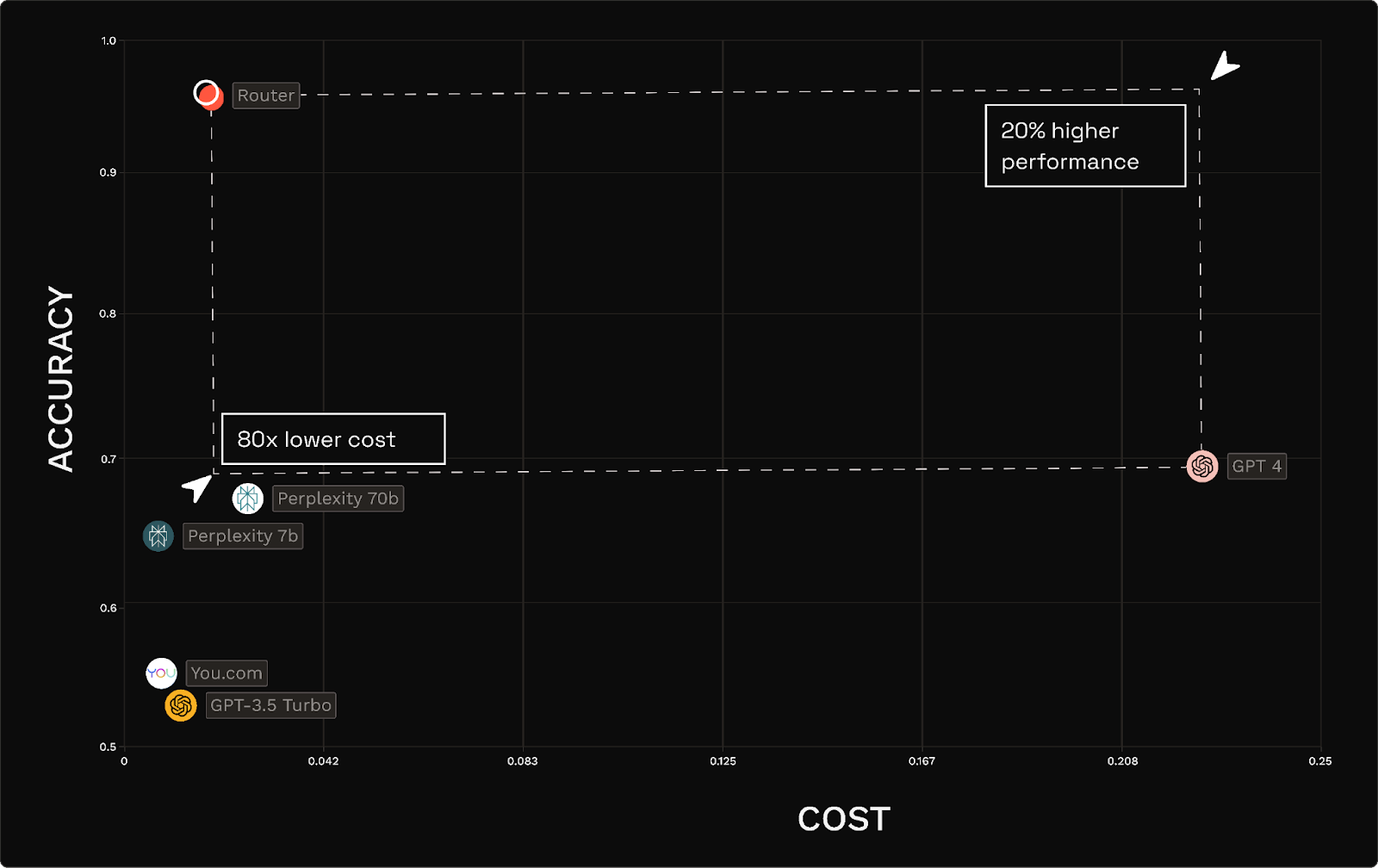
Consider the following example of retrieval augmented generation on customer data warehousing. Many companies would look at this result, note that GPT-4 has the highest accuracy (~70%) and conclude that they should be using GPT-4 for their RAG task because it appears to be “the best model”.
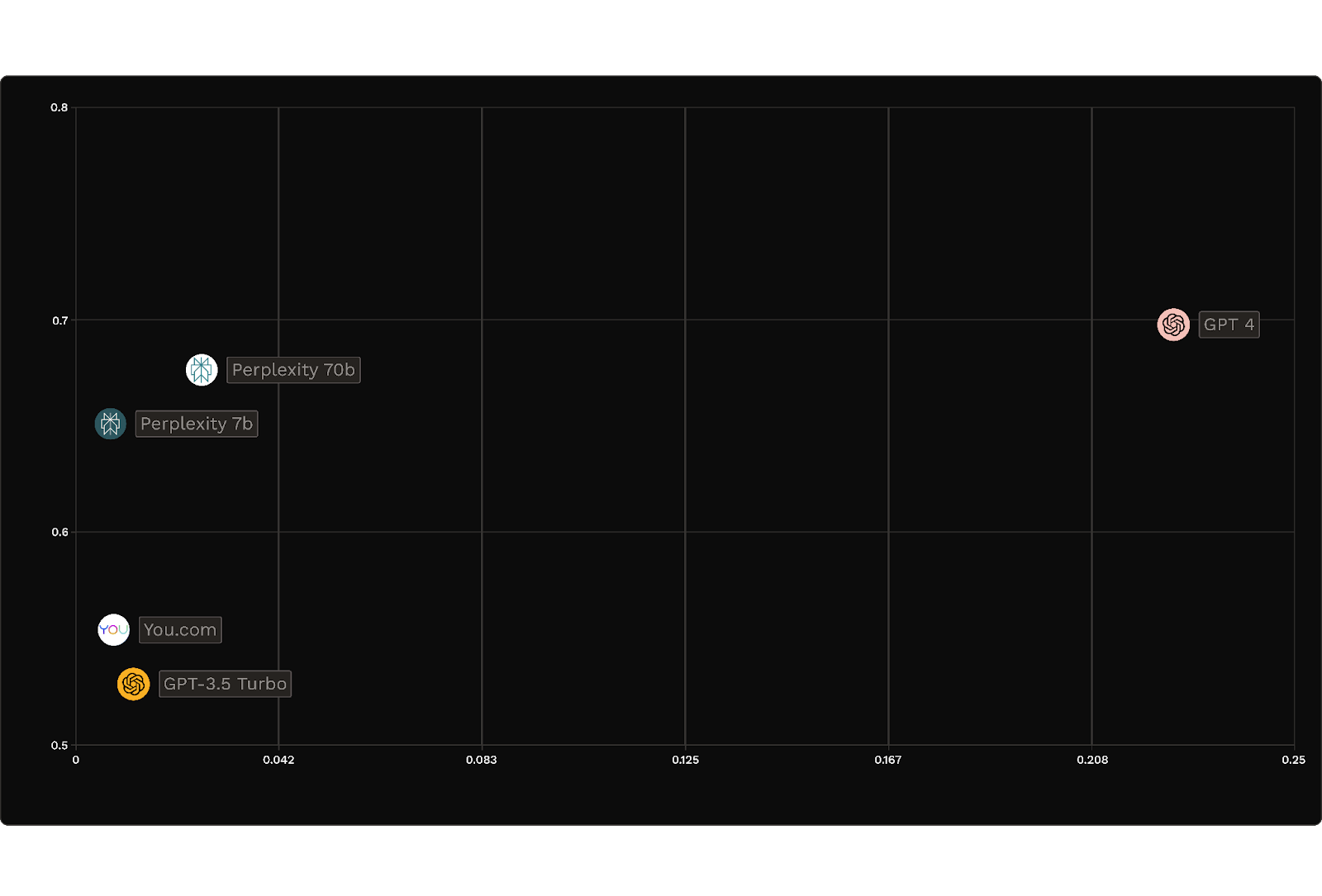
Yet Martian is able to achieve over 20% higher performance than GPT-4 (going from 70% to 95% accuracy) at 1/80th the cost.
This seems like something which relies on companies using many models. Are you betting on a multi-model future?
Surprisingly, it doesn’t take that many models to achieve good performance. Even with a handful of models – just those available from OpenAI and Anthropic – we’ve been able to see large gains from routing. And in practice, we route between vastly more models than that in order to achieve optimal performance.
That said, we’re fairly confident that the future is multi-model.
Firstly, companies want to avoid lock-in, and they want a mix of open source and closed source models to balance between factors like privacy and performance. But secondly, and more fundamentally, people are going to be using way more models in the future.
In the early days of any technology, it's usually super expensive to build whatever you're trying to build. If you look at the early Internet, you used to have incredible engineers build web servers in C if you wanted to release any kind of web app. It was really hard to put out a website back in the day, but now, as there's more tooling around this, building a web app is incredibly easy. Back when we were first building LLM apps, only OpenAI and Google were building LLMs, but we knew it was very unlikely that it would stay that way forever.
As access to data and compute is democratized, and as the algorithms get more efficient, anyone is going to be able to create their own LLMs. And there’s going to be an incentive to do so as well. Our view of the literature on training models is that models get good at understanding the data they’re trained on. They don’t, however, generalize well to data they haven’t seen before. When models look more generally intelligent, it’s because they’re trained on very general data from the internet. But as general data runs out and companies start to develop their proprietary sources of data, that will turn into proprietary models with proprietary capabilities.
In fact, one of our goals with an LLM router is also to create an incentive for people to create more models. Today, if you make a model that’s better in some niche area, you have to publicize it heavily in order for it to be used. In a world with a successful model router, you can just plug in your model, and if it’s actually better, you make money. We hope the result of this is the proliferation of smaller, specialized tool AIs instead of a single homogenous model. We're building a world of “a plurality of humanity loving AGIs”, as Ilya puts it.

If there are many websites out there, the thing that's really useful is Google, because it lets you find the best site for whatever query you have. Similarly, if there are many LLMs out there, an LLM aggregator becomes really useful - a tool which can go and help you find the best LLM amongst many different ones.
We’ve actually believed in this thesis of a multi-model world for a long time. Back in 2020 when only OpenAI and Google were building LLMs, we actually started pursuing this thesis with research into using multiple models in production systems. That’s allowed us to build the most sophisticated systems for model routing.
You mentioned previously that Martian leads to a reduction in the total cost of your AI stack. Could you elaborate on that further? And won't that become less important in this world you're describing where the cost of models is falling?
Martian reduces the total cost of ownership for AI in two ways. The first is that we can route requests to the least expensive model capable of completing your task. We even let you set a cost threshold instead of selecting a model, and instead choose the model best suited for your query within that cost. This is useful for applications that need to make sure their unit economics work well. But it’s actually the less important way we reduce the total cost of ownership of AI for many of our customers.
To build a multi-model system, you have to first go through all the different models out there, then you have to vet and evaluate all of them (this is both in terms of performance and, for larger companies, compliance), and then you have to take care of all the nuances of putting them into production (integrations, hosting, all the model-specific nuances of fine-tuning and prompting, etc.) – and every time new models come out (like the new Claude models last week, or new open source models that are coming out every day) you have to do it all over again. Martian takes care of all of these pieces for you.
Obviously, as the number of models increases, this second component becomes more onerous, and the value that Martian provides in simplifying multi-model deployment increases. However, as the cost of AI goes down, we actually think the value of cost reduction becomes more important over time, due to a counterintuitive phenomenon known as Jevons paradox.
Jevons was an economist during the second industrial revolution who observed that as steam engines became more efficient and consumed less coal, the total consumption of coal went up. This is because as steam engines became less expensive, they could be applied to more places in an economically viable way.
This is the defining characteristic of a general purpose technology: it can be applied generally, and therefore as its cost goes down its usage increases. This is exactly what we’ve seen with computers, for example – even though each generation is more efficient than the last, the total electricity and cost spent on compute (e.g. in the cloud) has consistently increased, and spend management has become increasingly important.
If AI is truly a general purpose technology, as we believe it is, then Jevons paradox will also hold for AI, and as the cost of AI goes down the importance of efficiency will increase.
What does that future actually look like? How will AI models be used more? And how does this relate to LLM Orchestration?
There are many ways in which the use of AI will change in the future, but one that illustrates the point well is LLM agents.
Today, AI still needs high levels of human supervision because it can be compute-intensive and makes mistakes. We are heading towards more autonomous systems, with AI doing complex and multi-step tasks.
With autonomous AI taking more steps on its own, dynamic routing becomes increasingly important.
It needs a lot more compute, with each task involving thousands of steps. This will lead to significant costs, and major hardware strain due to computing load. Martian reduces computing costs and load through routing.
Each step will rely on the output from previous steps. Any drop in quality or reliability will cascade significantly through the entire workflow. If an agent takes 100 steps powered by a single model and that model has even a 1% error rate, the odds of the full execution being correct are only 37%. Martian maintains quality and reliability better than any single model by routing each request to the model that will handle it best.
Companies need more trust and visibility into AI systems to hand off important tasks to autonomous systems. Martian’s research in looking inside models will be crucial in maintaining trust and safety.
To put it another way, the value of AI is in automating intellectual labor: powering intellectual machines. Most orchestration solutions today are about how we build those machines – we’re big fans of tools like langchain that let you define an agent. But most traditional machines don’t have generators built into them. Instead, they are plugged into an outlet, which abstracts away all the difficulty of producing and using electricity. Our goal is to make using intelligence as easy as using electricity – stop worrying about where you get it, just get as much as you need as cheaply as possible.
Today’s physical machines are powered by electricity through the grid. Tomorrow’s intellectual machines will be powered by AI through Martian.
How does Martian help with trust, visibility, and reliability?
Martian's mission is to understand AI, and our work on interpretability is crucial to building trust in AI systems. Today, AI models are poorly understood black boxes - we know they take in inputs and produce outputs, but not how they arrive at those outputs.
Imagine if we understood computer programs as poorly as we understand AI models today. I give you a sorting algorithm, tell you "it generally sorts things but sometimes fails", let you see the inputs and outputs, and tell you that it runs on an x86 architecture. What could you do with that algorithm? You could mess around with how you formatted inputs to the algorithm to improve results ("prompt engineering"). And you might be able to add some quick fixes on specific outputs where it fails ("fine-tuning"). But all the tools available to programmers today - refactoring, editing, unit testing, formal verification, debuggers - none of them would be possible. Dealing with algorithms that worked this way would be a nightmare.
Unfortunately, that's exactly the state of AI today. We know models take in text and spit out text. We know they run on a transformer architecture. And... that's it. We're in the dark ages of AI development.
Now, imagine if we could take a transformer model and turn it into a human-readable computer program. Suddenly, the full suite of software engineering tools and practices becomes possible. We can find bugs and fix them at the source. We can refactor models into cleaner, more modular architectures. We can write tests and formally verify key properties. This would revolutionize our ability to understand, trust and rely on AI.
At Martian, this is exactly what we're working towards. Ben, who I mentioned joined us from UPenn, is working on new techniques to extract key features and algorithms from transformer models - information we can use to boost the performance of our routing in the short term, but that will ultimately allow us to decompile transformers into fully transparent code.
We envision a future where AI systems are not opaque and unreliable, but transparent and robust. Where we don't just probe them from the outside, but can examine and improve their inner workings, like any other software. Making this a reality is core to Martian's mission. The interpretability research powering our model router today is the foundation for the transparent, trustworthy AI systems of tomorrow. And as AI becomes more widespread, we think that understanding will produce the most important set of tools for using AI effectively.
You mentioned that this mission has been exciting to customers, engineers, and researchers. What should people do if they're interested in working with you?
Customer should sign up on our website: withmartian.com
Potential hires should apply to the roles we have open.
We’re excited to understand AI and to work with so many awesome people!
Conclusion
To stay up to date on the latest with Martian, follow them on X(@withmartian) and learn more at Martian.
Read our past few Deep Dives below:
If you would like us to ‘Deep Dive’ a founder, team or product launch, please reply to this email ([email protected]) or DM us on Twitter or LinkedIn.