- Cerebral Valley
- Posts
- Gimlet is Making AI Infrastructure 10X More Powerful By Mixing GPUs, CPUs, and Accelerators ⚡
Gimlet is Making AI Infrastructure 10X More Powerful By Mixing GPUs, CPUs, and Accelerators ⚡
Plus: Co-Founder & CEO Zain Asgar on the "Inference Speed Wars", why the CUDA wall is a misconception, and how heterogeneous hardware delivers 3-10X faster inference for the same power envelope...
Cerebral Valley
March 26, 2026

CV Deep Dive
Today, we're talking with Zain Asgar, Co-Founder & CEO of Gimlet Labs.
Gimlet is an inference cloud designed to run agents, a software layer that breaks agentic workloads apart and maps each piece to whatever hardware runs it best. As the industry’s first multi-silicon inference cloud, they deploy agents across heterogeneous hardware from different generations, vendors, and chip architectures to deliver 3-10X faster for the same power envelope. Gimlet serves frontier AI labs, large-scale AI-native companies, and sovereign cloud providers.
Earlier this week, Gimlet announced an $80M Series A led by Menlo Ventures and joined by Eclipse, Factory, Prosperity7, and Triatomic. The company emerged from stealth in October 2025 with 8-figure revenues. Since then, the customer base has tripled.
Zain's career spans GPU silicon design at NVIDIA, Google AI (where his work became Google Lens), co-founding Pixie Labs (acquired by New Relic), and an ongoing role as Adjunct Professor at Stanford, where he co-leads the Portable Accelerator Group. The founding team - Zain, Michelle Nguyen, Omid Azizi, James Bartlett, and Natalie Serrino - brings together deep expertise across hardware, compilers, distributed systems, and developer tooling.
In this conversation, Zain walks us through the "Inference Speed Wars", how Gimlet's "three-layer cake" architecture disaggregates workloads across heterogeneous hardware, why the CUDA wall is a misconception, and what building critical infrastructure as a startup actually takes.
Let’s dive in ⚡️
Read time: 8 mins
Our Chat with Zain 💬
Zain, welcome to Cerebral Valley! You just announced an $80M Series A from Menlo Ventures. You've talked about the industry being in the middle of "Inference Speed Wars" - what does that mean?
I think inference is becoming the defining infrastructure problem of this era, and it's gotten way more urgent because of agents. Every major frontier lab is spending billions trying to get agent latency down, because agents are on the critical path of real workflows now. They're producing way more tokens than a chat model ever did.
Think about a coding agent, for example. It's ingesting your whole codebase, running inference repeatedly, and calling tools, and so latency compounds at every step. It's great that I can use a coding agent and write a bunch of code, but I also get really annoyed when I'm sitting there waiting - can't you just write this a little faster? And that's with a human in the loop. Increasingly, agents are also talking to other agents, not humans, so they can consume tokens as fast as you can serve them. There's no "reading speed" bottleneck anymore. If we can make runtimes 10X faster for the same power or cost, it fundamentally changes what you can build and how people interact with agents and AI.
The challenge we have is, the infrastructure everyone's running on was built for a different set of workloads.
Paint the picture for us, if you could, what does AI infrastructure look like today, and why is so much of it wasted?
If you take a look at any of the large-scale AI deployments, there's a lot of capex being spent - hundreds of billions. But utilization is somewhere between 10% and 50% depending on who you ask. Even at 20%, that's $140 billion of useful work out of $700 billion. The rest is waste.
The core issue is that almost everything runs on a single type of hardware. GPUs are incredible systems - I've worked on them - I still think they're on the Pareto-efficient frontier. But inference is fundamentally heterogeneous. Even within a single LLM call, prefill is compute-bound while decode is memory-bandwidth-bound. Add in multimodal workloads like image, video, and audio, and each modality brings its own compute profile. If you run all of that on the same chip, you're always over-provisioning on one axis and under-utilizing on another.
Agents make this even more urgent, because you're chaining models, calling tools, running code, all with different compute profiles. The inefficiency compounds at every step.
The reality is that GPUs, CPUs, and specialized accelerators all have a role, it just depends on the workload. GPUs and CPUs are each great at specific tasks, and there's another class of SRAM-centric chips from Groq, Cerebras, d-Matrix, and others that are incredibly well-suited for memory-bandwidth-heavy stages like decode. A lot of what we work on at Gimlet is how you blend different hardware together - chips that can serve out of SRAM for the high-speed work, GPUs for longer context work. The step-change performance comes from using them together, not picking one over the other.
Can you make that concrete for us? What does it actually look like when you run a workload across different hardware?
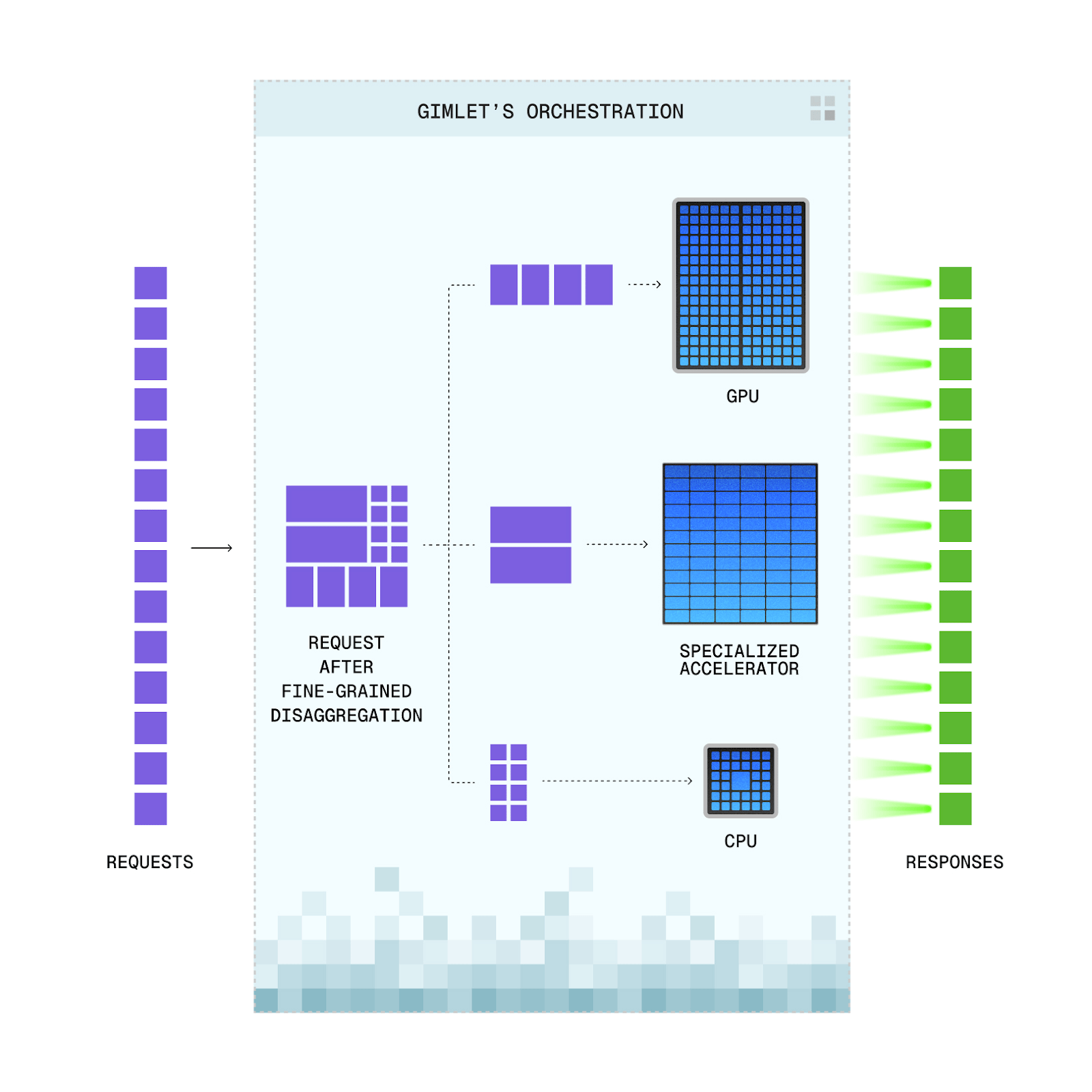
We initially started with prefill/decode disaggregation for LLMs. Prefill is massively parallel and compute-heavy, whereas decode is autoregressive and memory-bandwidth-heavy, so we separate them onto different hardware. But that's just one example. You can disaggregate across model layers, run attention and FFN on different hardware, and run non-model stages like tool calls or retrieval on CPUs.
Another application we're excited about for heterogeneous hardware is speculative decoding. One of our configurations uses a draft model, where the speculation step is memory-bandwidth-bound whereas the prefill and verification steps are compute-bound. So we ran the draft model on a d-Matrix Corsair, which has a lot of SRAM and about 20x the memory bandwidth of a high-end GPU, and kept prefill and verification on GPU. Compared to the same spec decode setup running entirely on GPU with the same exact power envelope, this gives 2–5x end-to-end speedups for interactive configurations, up to 10x for energy-optimized ones. A 20 second request becomes 2 seconds. That's the kind of step-change performance you can only get with heterogeneous configurations.
That software layer is doing a lot of heavy lifting. These chips weren't designed to work together, so what does it take to actually build that orchestration?
We talk about Gimlet's "three layers of the cake" internally.
The first layer is workload disaggregation: when you give us an entire agent graph, how do we carve it up - and even partition the underlying models - to map to specific hardware in the optimal way? That depends on what hardware is available.
The second layer is our dataflow compiler. It takes everything and lowers it to the target hardware - figuring out which phases of the data flow run where, what networking primitives need to exist between machines, and doing all that modeling.
The third layer is our kernel synthesis project, kforge. How do you optimize the code for each of these hardware targets? This is the only piece we don’t run live. When you upload a new model, it doesn’t autogenerate kernels for you because it’s still very much a research system we’re developing. I’m always careful not to oversell the automation. Most of our system does everything very automatically, but we generate all the kernels manually so we can verify they’re actually correct - there’s an entire challenge with automatically generated code.
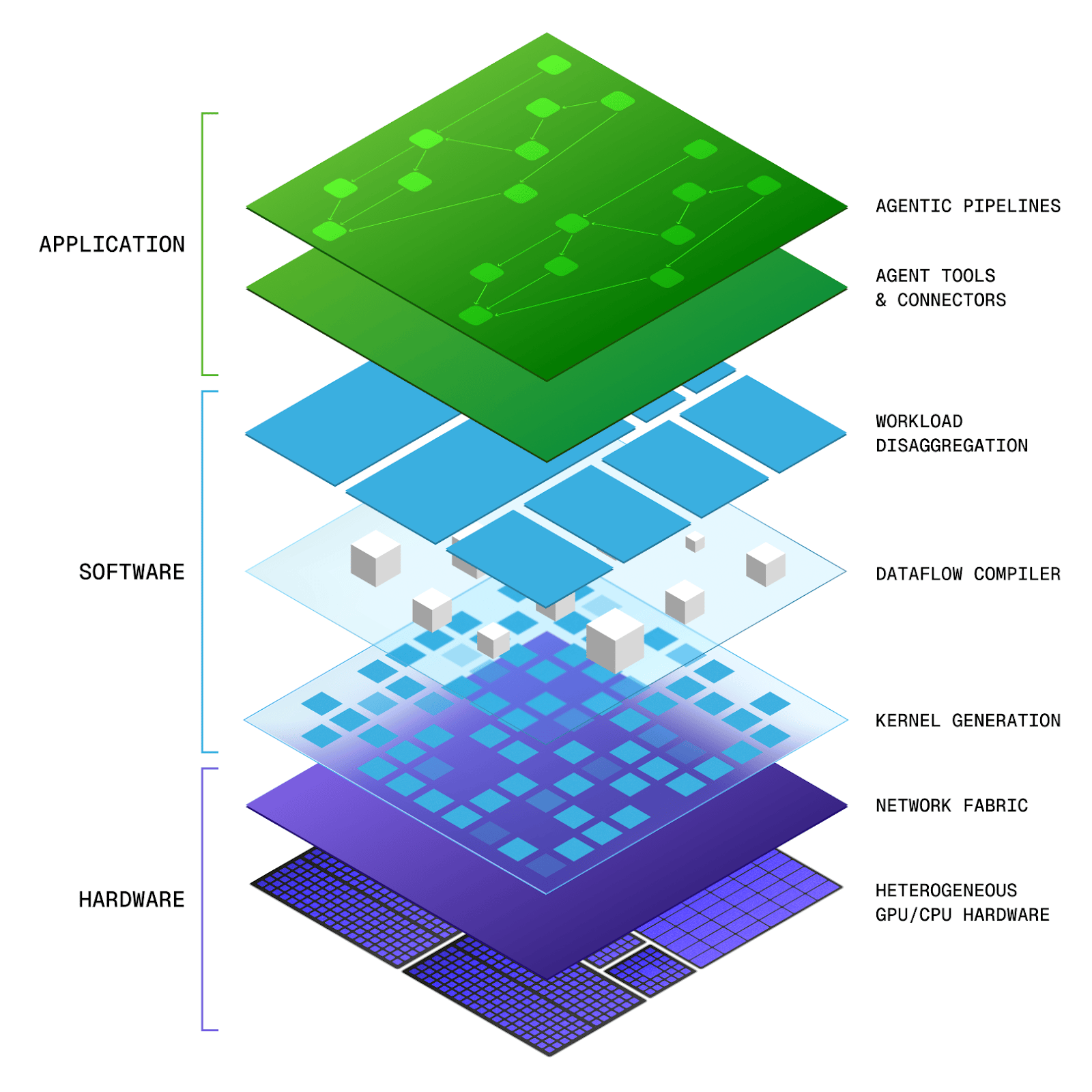
You support NVIDIA, Intel, AMD, and different generations within each. What are the hardest engineering challenges in making workloads portable across that much hardware diversity?
Whenever people start talking about porting models, they bring up the CUDA wall. I fundamentally don’t think that’s the real challenge. That’s maybe my hot take. People say “CUDA wall” because they took CUDA code, tried to run it on an AMD machine by modifying it, and it didn’t work. But it’s not CUDA that’s the issue - the architectures are different enough that you can’t just take code that works on an H100 and run it on an MI355 and hope it works.
The reality is, the same is true within a single vendor. You can’t just take code that runs on an H100, run it on a B200, and pray that it’s going to be performant. How you write kernels for Blackwell - or even different versions of Blackwell - is very different from how you would write kernels for a Hopper chip.
The portability problem isn't about the language. It's about getting a very deep understanding of the underlying hardware: how they think about data types, how they're processed, what the memory structures are.
Orchestration across different hardware platforms is also a major challenge. It's not necessarily easy to get data from an NVIDIA chip into the memory of an AMD chip. In some cases we bounce the memory through the CPU; in others we have some interesting approaches that try to memory-map data and pass it through. The goal is almost always to hide any memory transfers by overlapping compute. Unless you can hide the latency, performance degrades very rapidly.
Here's a fun fact: even within a single chip vendor across generations, they sometimes can't agree on the formats of things like KV caches or exact data types. So we either have to create a kernel that's consistent or add in the appropriate data transformations.
You emerged from stealth with 8-figure revenues, which is remarkable. Who's actually adopting Gimlet, and what's pulling them in?
We typically target three types of companies. The first group is the frontier AI labs - the large-scale foundation model labs. They have at-scale deployments, and we have a very compelling value proposition for them. We're now working directly with a top frontier lab.
The second group is AI-native companies - think about the largest, most successful companies from the last two to four years. Our customer profile in general: they have to be at scale, otherwise the types of problems we solve just aren't that interesting to them. They won't see the deltas they'd want if they're not hitting that level.
The third profile is sovereign neoclouds and similar infrastructure players. While we are a neocloud ourselves, we also operate our software on top of other people's hardware. Hardware capacity is pretty hard to come by, so we both source capacity from others and provide our software to help them utilize theirs.
The foundation labs and the neoclouds are definitely in the self-hosted camp, because you're essentially running on top of someone else's hardware. The AI natives are most definitely in the "just give me an API" camp. I think that split is going to stay.
Switching gears a little: you've had one of the more unique career arcs in AI, and the Gimlet founding team all came from your last company. Walk us through that journey.
Going in chronological order - I started working at NVIDIA on pretty deep hardware design. My career at NVIDIA spanned all the way from circuit design to architecture and into the software stack, because I actually started interning there as an undergrad and did my entire PhD while working there. My PhD focused on energy-efficient GPUs, which was a full-stack problem that required work from software to architecture.
At NVIDIA, I had spent a lot of time applying ML to optimization problems, which pulled me deeper into the ML side of things. That shift led me to Trifacta, which was focused on building systems for the emerging big data and ML wave. A theme that’s carried through my career is this interplay between ML and systems: using ML to improve systems, and building systems to support ML.
From there I went to Google AI, where I continued building systems for ML. I worked on on-device AI - specifically this project called Visual Semantic Lift, which turned into Google Lens. We were doing real-time image search and figuring out how to map that onto edge hardware like cell phones.
Then came Pixie Labs, where the goal was to build large-scale observability. We believed we could create an infinite amount of telemetry data using eBPF, then use ML to sort it all out and make systems problems cleaner and easier to understand. We ultimately got acquired by New Relic pretty quickly.
Once I left New Relic, the team got back together and we started Gimlet. A large part of the Gimlet team comes from the original Pixie team. I think everybody who was at Pixie went on to either start their own company or join Gimlet. Pixie had already pulled together people I went to grad school with, plus folks from Trifacta and Google. Gimlet pulled from that same pool. We were about 10 people at the beginning of last year, exited the year at about 29, and we're probably going to close to double in the next six months.
Pixie was an infrastructure company too. What did building it teach you about selling critical infrastructure as a startup?
On the infrastructure side, it's always difficult to convince somebody to adopt you when you're a very critical part of their system. It's a huge risk for anyone to take on your startup. The value proposition has to be extremely clear, and it can't be 20% better - usually you have to target multiple X's of improvement, and it has to be unique enough that they can't or (don’t want to) very quickly replicate it in-house. Because the first question is always: they'll go talk to their engineering teams and ask, "How long will it take us to do this ourselves?"
I think Pixie was somewhat of a peacetime company and Gimlet is a wartime company. The AI space moves so fast, and every week there's something new going on. The company feels very different, but we still have a lot of the same values - a very high-trust culture, very flat. I still write a lot of code every day.
If Gimlet delivers on the performance promise within the same power envelope, what exactly does that unlock?
Everyone talks about how we're out of power, we can't build anymore. Chip supply is another major constraint. If you can get 5 to 10X more performance out of the hardware you already have, that's the same as getting 5 to 10X more power or 5 to 10X more chips.
Agents are on the critical path of real products now. When those are slow, the whole product is slow, and it limits what you can actually do. 5-10X faster inference fundamentally changes what you can build and how people interact with it.
The performance demands are only going to get bigger as we move to multi-agent systems. Right now most agent traffic still has a human in the loop. When agents coordinate with other agents, the token volume and latency requirements will shift again dramatically. To serve those workloads, we're going to need to leverage all of the categories of hardware where they perform best.
You're 30 people with 8-figure revenue, a frontier lab as a customer, and $80M in fresh capital. What are you looking for, and why should someone join now?
We're a 100% in-person team, all based in San Francisco. Over the next six months, we're probably going to double if not more.
We hold a lot of execution risk right now, and I actually view that as the most positive thing to hold, because it's solvable. Our product-market risk is pretty low and our differentiation is pretty high. So the biggest thing we hold is our ability to build, deliver, and execute - which is great because we can control that.
We don't separate research and engineering because we think it needs to be done together to get the best results. Everyone's role is a bit of research and a bit of engineering - maybe a lot of one or the other.
We're hiring across all layers of the stack - and I literally mean all layers. We have everything from data center system stuff - how do we put all these machines together, the plumbing, the electrical, especially across heterogeneous hardware - to writing optimized kernels, to distributed systems work. We're building a large-scale service that's going to serve tens, if not hundreds, of megawatts of capacity in the near term. This is an opportunity to help define what the datacenters of the future will look like. We're still early enough that every engineer that joins can have a huge impact on the system. If this sounds exciting to you, we should talk.
Learn more at gimletlabs.ai · Open roles at jobs.ashbyhq.com/gimlet
Stay up to date on the latest with Gimlet, follow them here.
Read our past few Deep Dives below:
If you would like us to ‘Deep Dive’ a founder, team or product launch, please reply to this email ([email protected]) or DM us on Twitter or LinkedIn.