
CV Deep Dive
Today, we’re talking with Zach Koch and Justin Uberti, Co-Founders of Fixie.
Fixie enables AI to communicate as naturally as humans do. Founded by Zach and Justin in 2022, Fixie’s mission is to make AI conversations feel indistinguishable from those with real people - this means more fluid responses, human-like tone, and better comprehension overall.
At the heart of this mission is Ultravox – a new multimodal model that is trained to understand both text and human speech without the need for separate ASR or TTS stages (TTS coming soon). By consuming speech directly, Ultravox can be trained to understand the nuances of human dialogue such as emotion, interruptions, and more. Ultravox is fully open source.
Today, Fixie supports a variety of powerful use cases, including entertainment, in-product assistants, and customer support. In this conversation, Zach and Justin take us through the founding story of Fixie, their vision of building natural, human-like AI conversations, and Fixie’s roadmap for the next 6-12 months.
Let’s dive in ⚡️
Read time: 8 mins
Our Chat with Zach and Justin 💬
Zach and Justin - welcome to Cerebral Valley. First off, just give us a bit of background on yourselves and how you both met, and then what led you to start working together on Fixie?
Zach: Hey there! We started Fixie a little over two years ago, making an early bet on large language models, right before the ChatGPT era. We both have backgrounds at Google, where we overlapped, and we've been working on Fixie for nearly two years now, coming up in September. Justin’s background is in software engineering, and I've spent most of my time in product management roles at Google and Shopify.
Justin: I was at Google for 15 years and saw a lot of AI technology being developed during that time. However, I was working in a different department focusing on audio, video, and communication, building the first versions of the Google Meet service we're using right now. One thing that always struck me was that we’d ultimately want to use this sort of technology to interact with AIs in the future. But it was a theoretical problem for a long time until these sorts of models and APIs became available, enabling AI to do things that I didn't realize were possible.
I'd been considering leaving Google for a while, and the availability of this technology made me think it was an amazing time to start a company. Zach and I discussed this over the summer of 2022 and decided it was a great time to ride the wave of this new platform shift. So, it's been quite a ride. Over the past year and a half, we've been trying to understand how to shape this amazing technology into an interesting product or service that people will love to use.
Give us a top level overview of Fixie as it stands today - how would you describe the startup to those who are maybe less familiar with you?
The way we often describe Fixie is that we're trying to build AIs that you can talk to just like you talk to other humans. That's our goal. For people who might not be familiar with the concept, we sometimes use C-3PO as a frame of reference. C-3PO is a very human-like AI who engages in natural conversations and can participate in group discussions. You really think of him as another human almost. While he sounds a bit robotic—that's part of his charm—his interactions are quite human-like.
In the present moment, we have the inverse of C-3PO. We have very human-sounding voices, but the way they engage in conversations isn't as natural as our human interactions. To achieve that, we need new approaches. We need models that aren't just designed to be text-first but are actually voice-first, trained to learn the subtle nuances of human dialogue. We have all these social rules in how we converse: knowing when the user is done talking, when it's our turn to speak, using verbal affirmations like "yeah, yeah," polite ways to interrupt, and intonations that guide us.
All of these subtle social cues need to be taught to the model for it to have good conversations. So, we're focused on building both the models necessary for this and the infrastructure to support it. Most models today provide a simple HTTP endpoint where you call it and pass in some text. That approach doesn't work when you need to engage in back-and-forth dialogue in under 200 milliseconds. You need a completely different architectural stack for that.
Voice has seen an explosion of interest in 2024 as models get more capable and latency goes down. What drove you both towards the space of speech-to-speech, or AI-powered voice interactions?
The thing we've really been focusing on, and where we’ve spent a lot of time in the past, is the idea of making AIs almost human in terms of their interactions. They have the ability to talk and sound very human-like, even though the process underneath is quite different. So why do we interact with them through a command line? Why are we still using a text interface to type queries and get responses, much like a modern-day search engine? Why don't we just talk to them the same way we talk to humans?
When humans want to have a real, engaging conversation, they prefer face-to-face interaction. It's how we've learned to communicate over millions of years, utilizing the full range of our faculties. We thought this would be the right direction for AI as well—to have AI that can communicate with nuance in its voice, understand not just the text but also the tone of what you're saying, and make the interaction more engaging. Our goal is to create a communication experience where you can't tell if you're talking to a human or an AI. To achieve this, the AI has to be fully embodied in something that acts and sounds genuinely human.
We've been on that quest, and Fixie's been focused on this over the past nine months, trying to attack this problem from a variety of different angles.
In terms of developments in the AI voice world this year, GPT4o’s unveiling was a massive moment for the entire ecosystem. How do you perceive what that really means for companies that are pursuing the idea of speech-to-speech?
During the GPT-4o unveiling, they talked about three things in the actual demo video. The first one was speed, responding in 300 milliseconds. We thought this was a critical part of what was missing in a lot of the voice interactions that existed to date. Things like Siri and Google Assistant often have multi-second pauses before the system responds. It's like sending a chat message with your voice; it wasn't really a conversation. We wanted to move past that paradigm into the paradigm where you really felt like you were having a voice conversation, and the illusion was created of talking to another human.
The second was interruptions. You shouldn't have this rigid turn-taking because that's not how human conversation works. People say, "Oh, wait a second," as part of the natural flow of a conversation. It's a two-way protocol, not just "You go, then I go." The last thing was emotional context and paralinguistic information. Speech contains more than just semantics and textual meaning. There's how you say it, the rate at which you say it, the tone. Even just talking to someone, you get a sense of a familiar or friendly voice. All these nuances that humans understand almost from birth are missing in the text domain. They basically highlighted these points, which we've been emphasizing for a long time.
GPT-4o really put a spotlight on the category, which is extremely exciting because we've been talking about this for a long time now. The flip side is that now you have the biggest frontier AI lab working in the same direction you've been working in. The question is, what does that mean? Are you just going to get steamrolled by their quest to be faster at everything? The one thing we took away is that if we get to a world where everyone is talking in this multimodal, conversational, embodied AI way, that's the future we've been envisioning. If it arrives faster, that's an interesting place for us. Now, the question is how do we handle the second aspect of that?
Let’s talk about Ultravox, which is Fixie’s open-source project that has gained a lot of attention recently. How does this fit in with your overall plans for Fixie?
Ultravox, as an open-source project, allows us to navigate this landscape differently. Instead of trying to compete directly as a small startup with a major AI lab, we're saying, "Here's the future. OpenAI has given a demonstration, and we're pursuing this vision too. Join us on this quest."
With Ultravox, you don’t have to be dependent on OpenAI's closed models and datasets. You can build on our open-source foundation. We're collaborating with the open-source community and building on projects like Meta's LLaMA to replicate the same kind of advancements in a more controllable and accessible way for your specific application. There are plenty of examples of this dynamic working successfully in the past, and we're here as the first ones to do this in the open-source world. Plus, we're already shipping, whereas GPT-4o is still just an announcement. That’s a strong position for us to be in.
If you watch the GPT-4o announcement, it's quite magical, but you also notice a lot of challenges. The model gets confused about when it's its turn to speak and still struggles with interruptions. You think, "Okay, this is a giant frontier research lab, but they're still grappling with the same basic issues we are." These are difficult, unsolved problems. It's validating to see that the market is there and that what we've been saying is true. I joked while watching that they basically demonstrated our pitch deck. But there's also a lot of work to do. Even with our relatively small team, I think we're within striking range of what they've achieved.
The second thing is that the classic way other companies have been tackling this problem is what we call the discrete components approach. We need a more user-friendly term, but essentially, they pipeline an ASR system to an LLM to a TTS engine. Our deep thesis has always been that this approach will be insufficient. If you want really fast, low-latency, natural conversation, all these functions need to be integrated into a singular model. The discrete component approach is low-hanging fruit that doesn't make sense long-term. I think GPT-4o demonstrated that the right direction is these singular language models that handle everything. They will be far more effective than the sum of their parts in terms of ASR, LLM, and TTS.
How would you say Ultravox is architecturally or structurally different from the tools that other players in the space - excluding OpenAI - are putting out there? What’s unique about your approach?
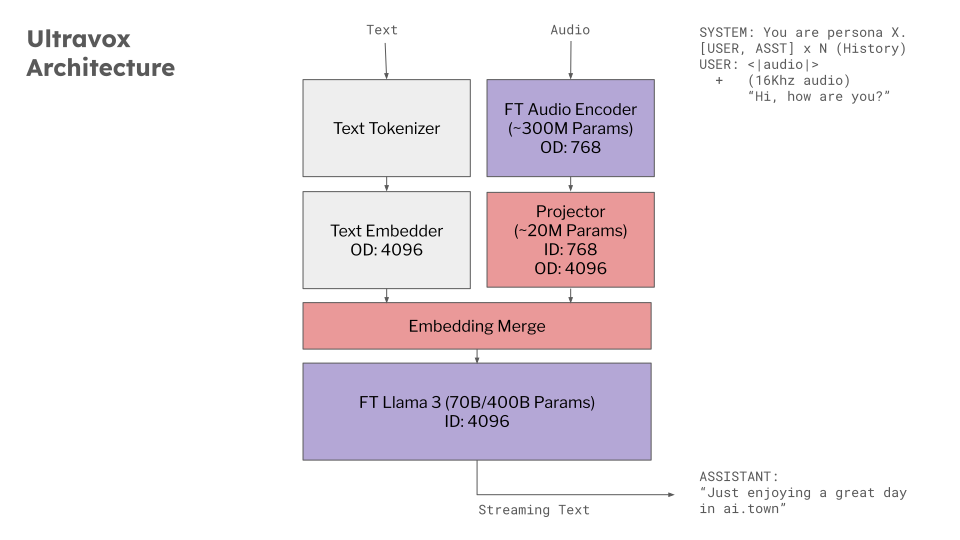
At a high level, almost every company in the speech-to-speech space outside of OpenAI or new entrants like Moshi, works the same way. They use a pipeline where an ASR provider, like Whisper, handles the front end. In the middle, there's the LLM. The job of the ASR is to strip all context from the audio and provide just the text, which is then passed to the LLM. Once the LLM processes it, it streams the output to a TTS provider.
At Fixie, we start with an existing LLM that's been pre-trained, like LLaMA 3. We add our encoder and projector to convert the data. These are much smaller models, with around 100 million parameters, not the billion-parameter scale, so we can train them quickly. This allows the existing frontier model like LLaMA 3 to natively understand the mapping from the speech domain into the world model it learned from pre-training. The real magic lies in removing the arbitrary border checkpoints from speechland into LLM land, enabling the model to consume information in its native embedding space.
We've seen an amazing example where you can speak to the model in a language it was never trained in, and it can understand that language natively. By giving it the information in its native language, it develops these deeper understandings. These observations show that it's a much richer form of information and will be far more flexible than the discrete components approach that Zach mentioned.
What's cool is that we've open-sourced the whole thing. It's right here for anyone to see at https://ultravox.ai (which is just a fancy URL pointing to a Github repo). We just open-sourced it a month ago, and we'll be building out in public from here on out.
Tell us a little bit about your target audience for Ultravox. In which areas are you most excited for the use-cases to come to fruition?
Our main focus is to grow and attract people into the Ultravox community and improve the capabilities of the speech-to-speech model. We've seen a lot of interest from companies in speech-to-speech systems and are working with a few of them. We can't share names, but we're always interested in providing access to those looking to incorporate voice as a big part of their offerings. We’re also working with partners to make it really easy for people to spin up their own, hosted versions of Ultravox. We’ve been working closely with the folks over at Baseten, and you can actually deploy your own version of Ultravox today through their model library.
Customer service is a classic application, but we’re thinking way beyond that. Much of our work gets done through voice, like in work meetings. There's a lot of potential unlocked by having a model that can engage in real-time, speak natively, and know when it's their turn to speak. We see a larger vision there. We also think there is a lot of low hanging fruit to go after. One example are those classic phone trees we all hate getting stuck in. Why can’t we just say exactly what we want? In the next few years, we think that solutions like Ultravox will allow companies to deliver better and cheaper experiences than they do today.
Lastly, we’re also developing our own demo application called Town where you can talk to different characters powered by our technology. Our sample character, Turbo Tara, is powered by Ultravox right now. It's a great way for people to try having a dialogue and experiment with it. Tara is currently running on version 0.2 of the model, and we'll probably have 0.3 next week. It's a good opportunity for people to test it out and see how it works in real-time. We're dedicated to perfecting the flow of conversation and getting the nuances of chitchat right.
What are your main priorities for the next 6-12 months? Any key areas of focus you’re going to be honing in on?
There are a few different things we’re focused on. The most important is continuing to deliver the core mission: building a model that allows for incredibly natural conversation. We’re happy with the start that we’ve made, but there’s a lot of work to do ().
The second is completing the vision - in terms of understanding tone and other paralinguistic cues, and getting more of the elements that take us beyond the discrete components.
The third is making this work naturally with other models, following where the open-source community is going, delivering quality, and figuring out the right benchmarks in the speech world. We want to drive the narrative around this new moment for speech LLMs.
Lastly, how big is the Fixie team?
We're a team of nine right now - with folks experienced in building back-end systems and everything involved in running and hosting a real-time speech model with low latency. We're actively growing our AI team. So come join us if you’re interested in building multi-modal models (careers.fixie.ai)!
Conclusion
Read our past few Deep Dives below:
If you would like us to ‘Deep Dive’ a founder, team or product launch, please reply to this email ([email protected]) or DM us on Twitter or LinkedIn.