
CV Deep Dive
Datasaur enables AI at enterprises with LLM Labs, designed to streamline the creation and deployment of private large language models (LLMs) for enterprises. Founded in 2019 by Ivan, who holds a computer science degree from Stanford and has extensive experience in AI solutions from his time at Apple, Datasaur aims to simplify and enhance the process of building and managing NLP models. However, the company got its start by providing a cutting-edge data labeling platform.
Ivan’s journey with Datasaur began with a focus on addressing the inefficiencies he witnessed in data labeling during his tenure at Apple, where spreadsheets were commonly used despite the substantial investments in AI. Recognizing a broader industry need, he launched Datasaur to provide a more efficient solution for turning raw data into structured datasets. With the advent of ChatGPT, Datasaur expanded its offerings to include LLM Labs, enabling organizations to build private, secure LLMs using their proprietary data.
Datasaur most recently raised in August 2023 from Initialized Ventures. Other backers include Greg Brockman, President of OpenAI, Calvin French-Owen, former CTO and co-founder of Segment, Hanover Technology Investment Group, and Gold House Ventures.
In this conversation, Ivan shares his insights on Datasaur’s LLM Labs, the technical challenges of integrating diverse AI technologies to existing enterprises, and the unique approach Datasaur brings.
Let’s dive in ⚡️
Read time: 8 mins
Our Chat with Ivan 💬
Ivan – welcome to Cerebral Valley! Please introduce yourself and give us a bit of background on yourself. What led you to found Datasaur?
Hi! My name is Ivan, and I'm the CEO and founder of Datasaur. We started this in 2019. I studied computer science at Stanford, and this is my second startup. Before this, I worked at Apple on some of their AI solutions, where we spent hundreds of millions of dollars gathering labeled data to power ML models, often using spreadsheets.
I founded Datasaur to solve this problem for the broader industry, making it easier to build and deploy NLP solutions and transform raw data into structured data to power these models. For the first three years, we focused on building an NLP labeling platform. However, with the announcement of ChatGPT about a year and a half ago, the NLP landscape changed significantly. We now have a second product called LLM Labs, which simplifies the process of building a private LLM for your organization using your proprietary data.
How would you describe Datasaur to the uninitiated ML developer or PM?
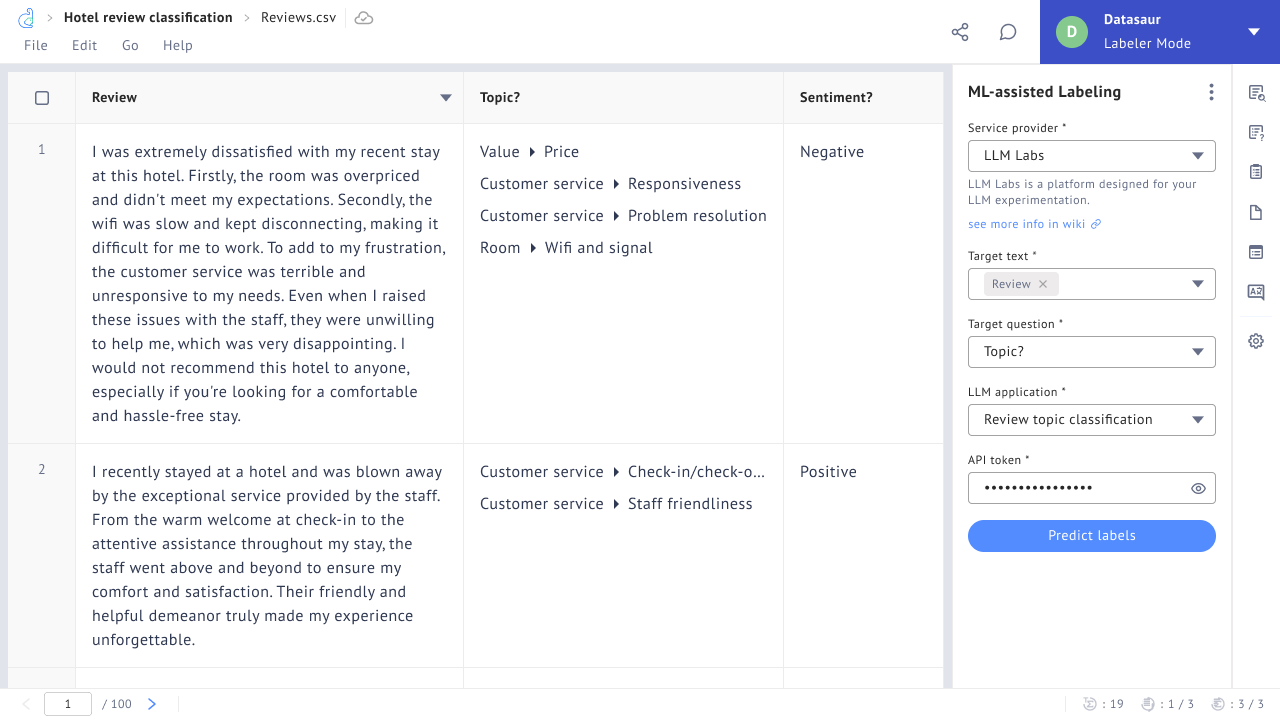
We actually have two products, but I want to focus on our second product, Datasaur LLM Labs. LLM Labs is a platform where you can build your own private LLMs. Many employees use ChatGPT at home and would like to use it for work, but that introduces risks of sharing proprietary information with third parties like OpenAI or Anthropic. LLM Labs helps organizations build and develop their own private LLMs atop foundation models like GPT 4o, Claude 3.5, Llama 3 and Gemini 1.5, connected to their proprietary databases and documents, in an interchangeable and dynamic way. These private LLMs help companies empower their staff to tap into AI for their work while steering clear of public AI tools that might raise red flags for security and compliance.
Open-source tools can be very effective, but require significant effort to install and deploy in an enterprise environment. On the other hand, proprietary solutions might lack the necessary compliance and regulatory certifications to pass through InfoSec. Datasaur caters to those who want a solution that can be deployed simply and directly to their servers while upholding the highest standards of security. In fact, with LLM Labs, a user with no ML background can deploy the latest state of the art model like Claude 3.5 with a RAG database in under 2 minutes flat!
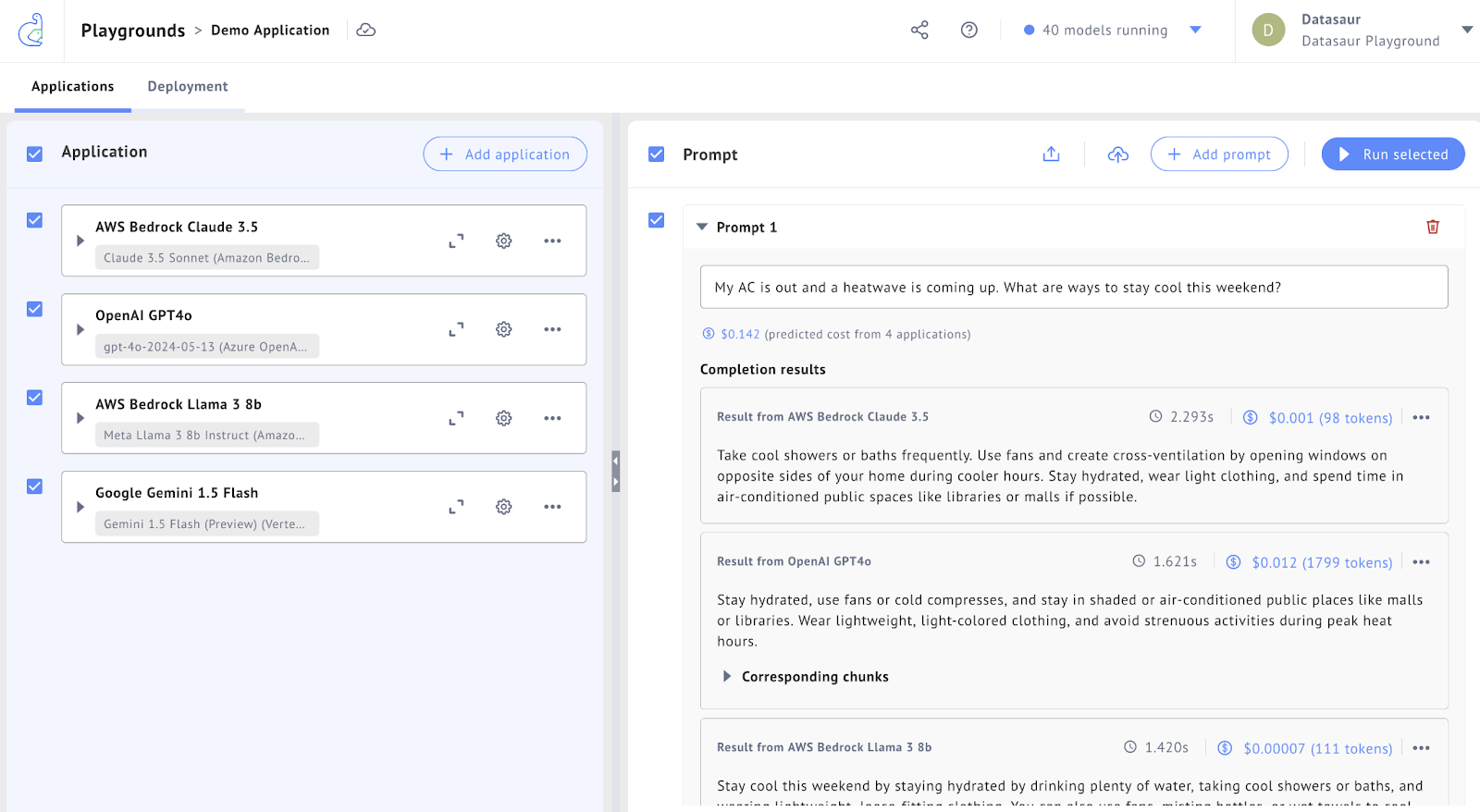
In the Datasaur Playground, directly compare state of the art models against one another, evaluating quality, inference speed and cost
One of the main pain points for data scientists today is the overwhelming number of options available. Should they use GPT-4, LLaMA 3, or Gemini 1.5? We help assess these different models, understanding not only the quality differences but also the time to inference and cost. Many companies struggle with scaling POCs built on ChatGPT to production, where calling the model 10 million times per month can become prohibitively expensive. Datasaur helps determine the best solution for their specific workflow, balancing quality, speed, and cost.
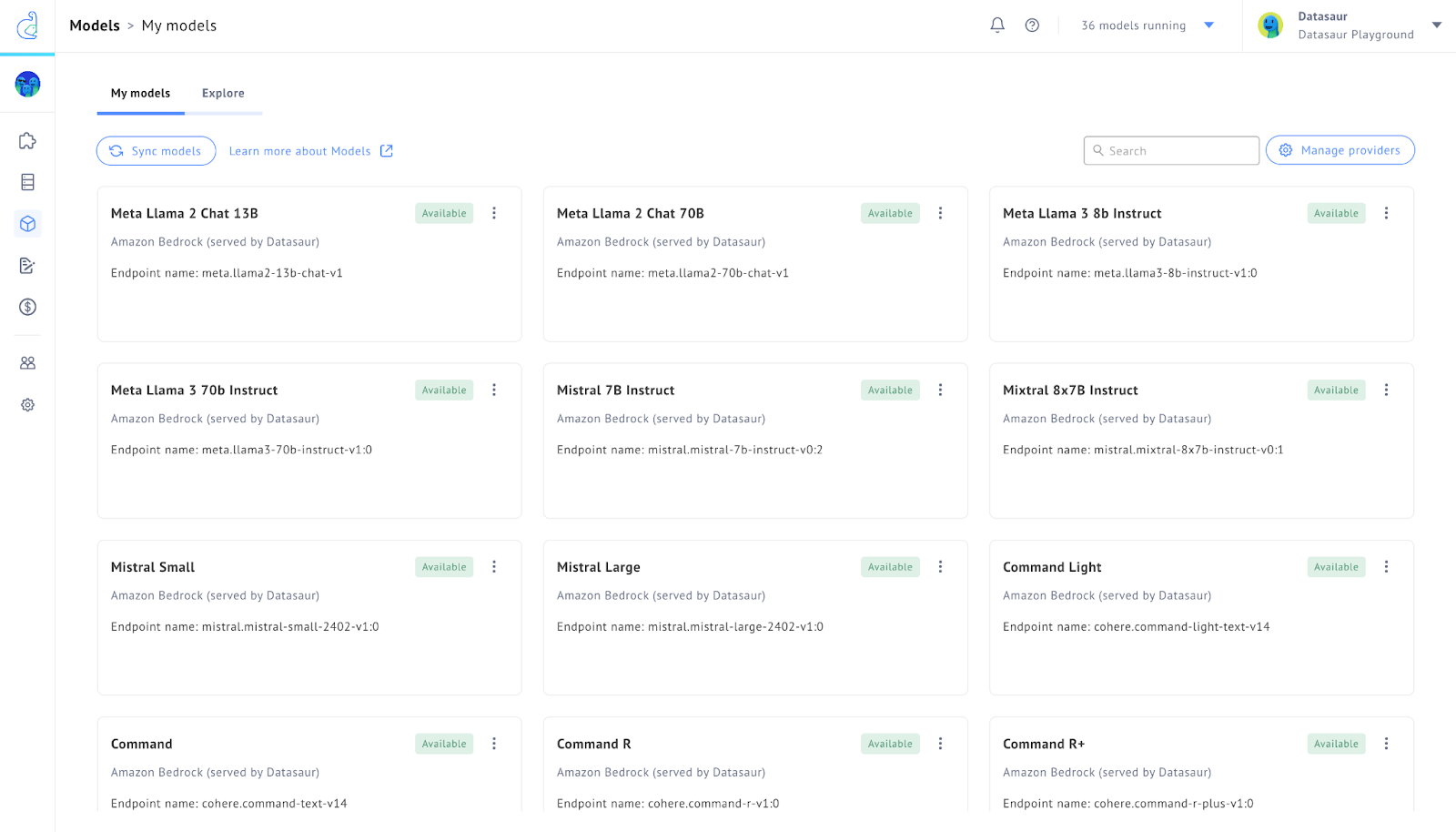
Datasaur offers over 200 foundation models to start from
Who do you sell to?
We primarily sell to data science organizations, including AI engineers and data scientists. These professionals find value in being able to interchangeably test different foundation models, embedding models, and vector store technologies in a scalable and cost-effective way. Once they're onboard, they often bring in subject matter experts. For example, in the insurance industry, licensed insurance agents might be needed to evaluate the quality of the results. This makes Datasaur LLM Labs not only useful for data scientists but also user-friendly for non-technical users who can provide accurate feedback on the quality of the answers without needing to understand all the technical details.
There is high demand for private LLMs for enterprise since the release of ChatGPT. Can you give us an overview of the landscape for private LLMs for enterprises, and what sets Datasaur apart?
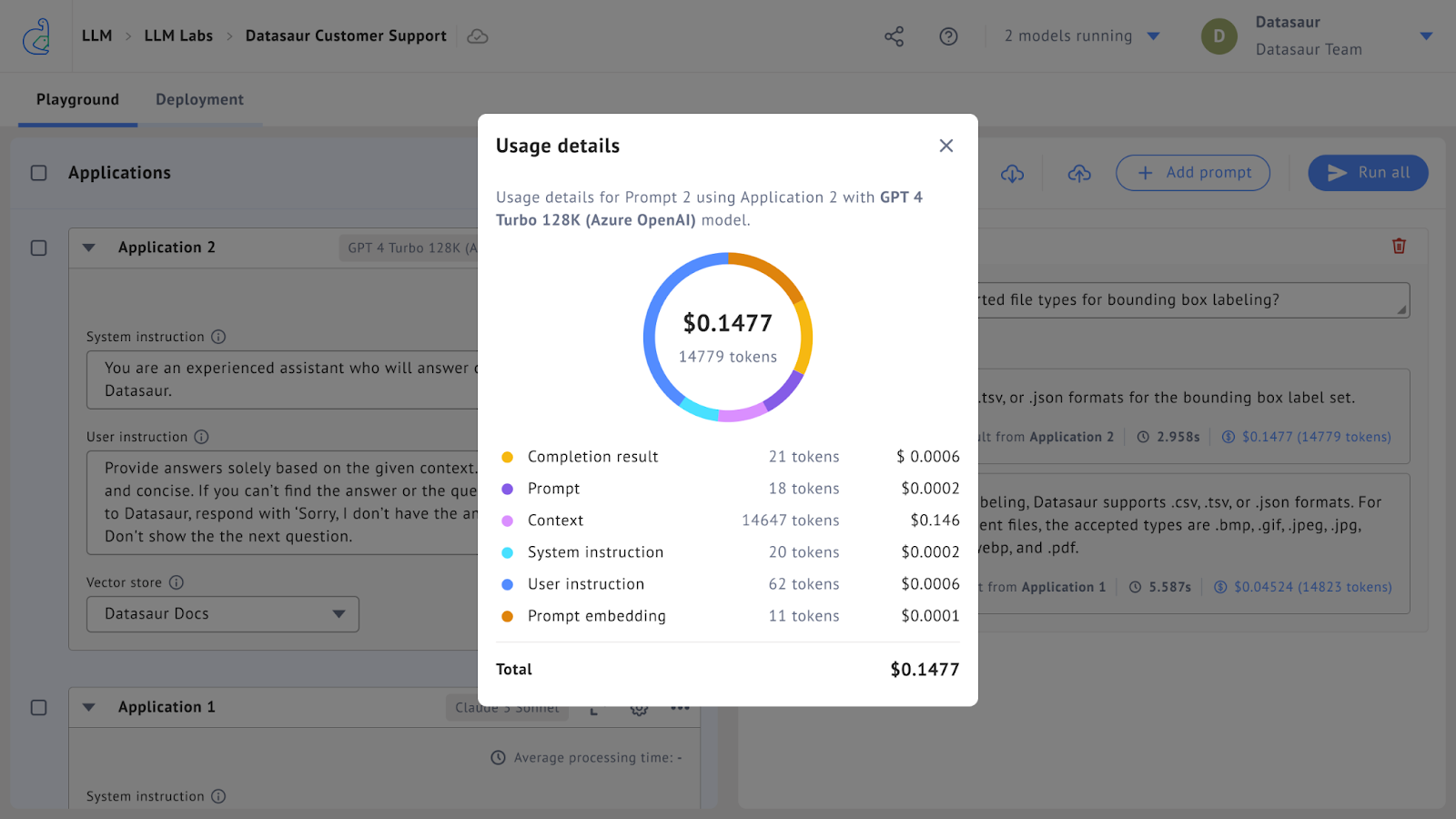
Datasaur also breaks down the costs for each query/inference
We are the only solution that allows you to compare quality, inference speed, and cost across 200+ foundation models, which is a unique differentiator. More broadly, we provide peace of mind to our users. For instance, if they commit to LLaMA 3 today, they can easily assess the gaps and benefits if GPT-5 arrives. This ensures they can commit comfortably without worrying about future advancements.
Datasaur makes uploading and connecting your own documents via Retrieval Augmented Generation (RAG) as easy as uploading to DropBox
We save your progress, including data chunking, embedding, prompt engineering, and the correct ground truth datasets. When a new model like GPT-5 comes out, you can swap it in, and we help evaluate if the new answers are close to the previously gathered correct answers. This allows seamless transitions between models while maintaining high-quality results.
What were some of the technical challenges you encountered while building Datasaur LLM Labs?
The technical challenges were unique due to the rapidly changing landscape. This is the fastest-growing and most dynamic ecosystem I've experienced in my career. One challenge was the lack of standardization in responses from different foundation models and embedding models. We had to build infrastructure to support various approaches, like those from Hugging Face versus AWS.
Identifying the most common technologies that people want integration with was another challenge. There are many startups and hot technologies, and people want us to integrate with their specific tech stack. We aimed to combine the best technologies while streamlining the user experience. Instead of offering too many options, we've done the heavy lifting to identify the models that benefit the most use cases.
Privacy and security are also significant concerns. Unlike startups catering to early adopters, we have an existing client base of enterprise and Fortune 500 companies. To ensure their adoption, we must be SOC 2, HIPAA and GDPR compliant, ensuring the highest level of security so they can responsibly adopt and use our platform.
Are there any particular customer success stories you'd like to share? How do you define success for Datasaur?
We define success by helping people migrate from a monolithic single cloud provider to the Datasaur platform. Not only do customers struggle with choosing single foundation models, but they also wonder whether to commit to Azure, Google, or AWS ecosystems. With Datasaur, they realize they have the freedom to pick and choose the best services and features from each. If Microsoft releases something unique in six months, they can easily switch and leverage that too.
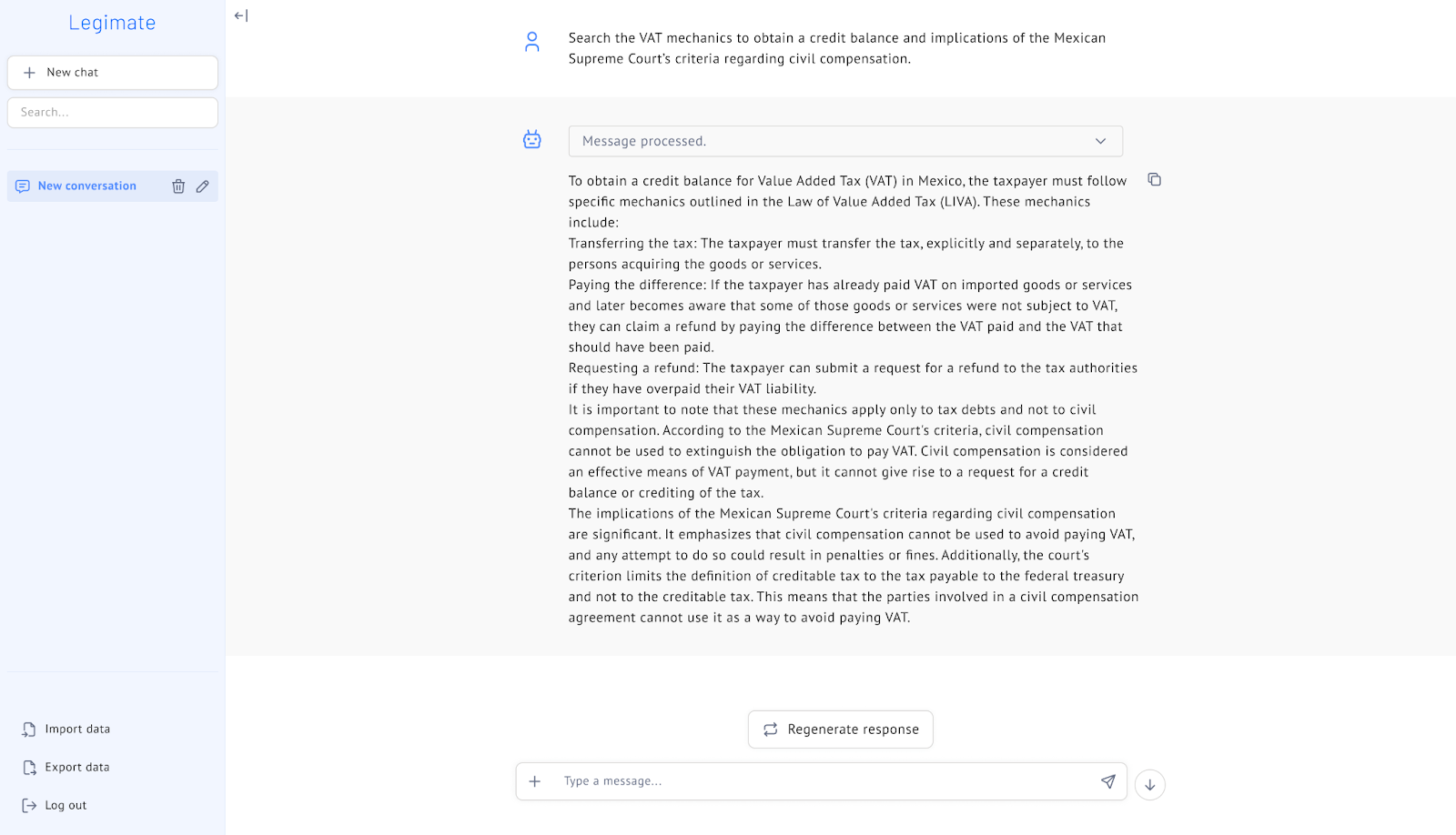
Our white label chatbot Legimate can be connected to models built in LLM Labs to support a ready-made ChatGPT-style application
We worked with a legal firm to build a solution that their lawyers could use without disclosing any legal or client data to cloud service providers. We focused on workflows that would provide the highest ROI from a business standpoint and identified four to five key workflows for a successful project.
We helped them navigate which foundation model would provide the highest quality results while meeting their security requirements. Based on their security team's needs, none of the proprietary models, including the enterprise version of OpenAI or Azure hosted environment, passed. We chose an open-source model, LLaMA, hosted on AWS.
We identified the foundation model, created prompts representative of their workflow, and iterated until we reached an agreed-upon quality threshold of 92% accuracy. The consistency of this accuracy was crucial - the base model with no fine tuning started at below 40% accuracy. Now, they operate with peace of mind, knowing that their queries are secure, none of their data leaves their servers, and the quality is high enough for daily use. Additionally, by deploying an open source model we were able to help deliver over 70% in monthly operational cost savings!
What are some of the techniques you use with Datasaur LLM Labs to ensure privacy and prevent data from being sent to the providers of the intelligence?
Part of our approach involves partnering with major cloud solutions. We’ve collaborated with our cloud partners to ensure best practices for deploying to our clients’ Virtual Private Cloud (VPC) environments. This includes direct API integrations for security and ease of use. Additionally, we continuously meet our obligations to security auditors, maintaining SOC 2, HIPAA and GDPR compliance.
A notable example is our contract with the FBI, where we deployed to AWS GovCloud to meet their high-security standards. This shows our ability to ensure privacy and security even in the most demanding environments.
How do you balance research and prioritization given the rapid pace of AI breakthroughs? Is Datasaur more focused on research or productization?
We focus on helping people build scalable enterprise solutions. While there are many tools and research papers that assist in creating proof of concept LLMs, our area of focus is on companies that have already validated their concepts and are looking to deploy in production.
For example, consider a call center. ChatGPT does a good job of masking inference time by typing out the answer, but in a call center, a 16-second delay is unacceptable. We help call centers evaluate technologies that can deliver high-quality answers much faster, even if it means insignificantly lower accuracy. This trade-off is crucial for customer retention.
Additionally, we assist companies in finding cost-effective solutions. While ChatGPT might be affordable for a POC with 100 queries a day, scaling to a million API calls a month becomes prohibitively expensive. We help find models that can be tuned to the same level of accuracy but at a significantly lower cost. These real-world cost savings—sometimes up to 20 times cheaper—are a major value add for our customers. This approach of optimizing for both performance and cost is our main focus.
How do you see Datasaur progressing over the next six to twelve months?
One trend in the broader industry is that LLMs won't be used for everything. For example, at Apple's recent WWDC, they announced Apple Intelligence AI for iPhones. Most queries will be handled on the device with a small, 3 billion parameter language model, and only the queries it can't answer will go to the cloud LLM.
In the enterprise world, we see a similar approach. Not every task requires an LLM. For instance, scanning a receipt to identify the subtotal, tip, and total doesn't need an LLM; a smaller, more efficient model can do it with greater accuracy, speed, and lower cost.
Over the next six to twelve months, we'll focus on helping organizations build and deploy any type of LLM solution they need. For rigorous workflows, we'll help build the appropriate LLM. For simpler, focused tasks, we'll train smaller models or even traditional NLP models. Regardless of the complexity of the task, we aim to be the comprehensive LLM/NLP provider for our clients.
Datasaur also supports LLM distillation - leveraging LLM intelligence to train a traditional NLP model
How would you describe the culture at Datasaur?
It's really exciting to be in the eye of the storm. One thing that’s served us well is that we have a learning-first mentality, sharing articles, videos, and summaries with one another to stay up-to-date in this rapidly evolving space. We also prioritize teamwork, putting egos aside to help each other out and focus on deliverables. We emphasize the end-user experience, empowering individual engineers to suggest features and work on initiatives that will truly benefit our users.
To learn more about LLM Labs and explore its features, visit https://datasaur.ai/llm/llm-home. We offer a free tier to get started. For additional information or to discuss potential use cases, you can reach out to us at [email protected].
Conclusion
To stay up to date on the latest with Datasaur, follow them on X and learn more about them at Datasaur.
Read our past few Deep Dives below:
If you would like us to ‘Deep Dive’ a founder, team or product launch, please reply to this email ([email protected]) or DM us on Twitter or LinkedIn.