
CV Deep Dive
Today, we’re talking with Vaibhav Gupta, CEO and Co-Founder of Boundary.
Boundary builds developer tooling for structured generation with LLMs. Their flagship product is BAML, an open-source domain-specific language to build, test, and manage prompts. Co-founded by Vaibhav and his co-founder Aaron Villalpando during YC’s W23 batch, Boundary’s mission originated from a desire to reduce hallucinations and provide guarantees on the outputs generated by AI models. BAML currently has compatibility with all major providers like OpenAI, Anthropic, Cohere, Gemini, and even local models.
Today, BAML is used by a range of AI-focused customers, from YC startups to mid-market enterprises and nonprofits, like MuckRock, for example, which uses BAML for processing FOIA requests. Developers love BAML for its fast iteration speed, VSCode LLM playground, and native Python/Typescript/Ruby integrations, making it a valuable tool for those aiming to achieve high levels of assurance and efficiency in their AI workflows.
In this conversation, Vaibhav takes us through the founding story of Boundary, the decision to make a new programming language, and their roadmap for the next 12 months.
Let’s dive in ⚡️
Read time: 8 mins
Our Chat with Vaibhav 💬
Vaibhav - welcome to Cerebral Valley! First off, give us a bit about your background and what led you to co-found Boundary?
I came from working in industry for the last ten years, focusing on computer vision and other AI problems. Some notable projects I worked on include Face ID at Google, AR teams at Microsoft, and optimization work at D. E. Shaw. The most common challenge I saw with AI systems is that they are probabilistic in nature—they sometimes fail and sometimes succeed. Most people are used to software that responds in a very specific, expected, and consistent manner.
With Boundary, our goal is to help developers have guarantees so probabilistic systems like LLMs behave like deterministic, reliable systems like banking or database software.
Give us a top-level overview of BAML - how would you describe it to the uninitiated AI/ML developer or enterprise team?
BAML helps you write your prompts as functions in BAML files, with expected input types that produce expected output types. The main innovation is the idea of prompt engineering with data types, not just English.
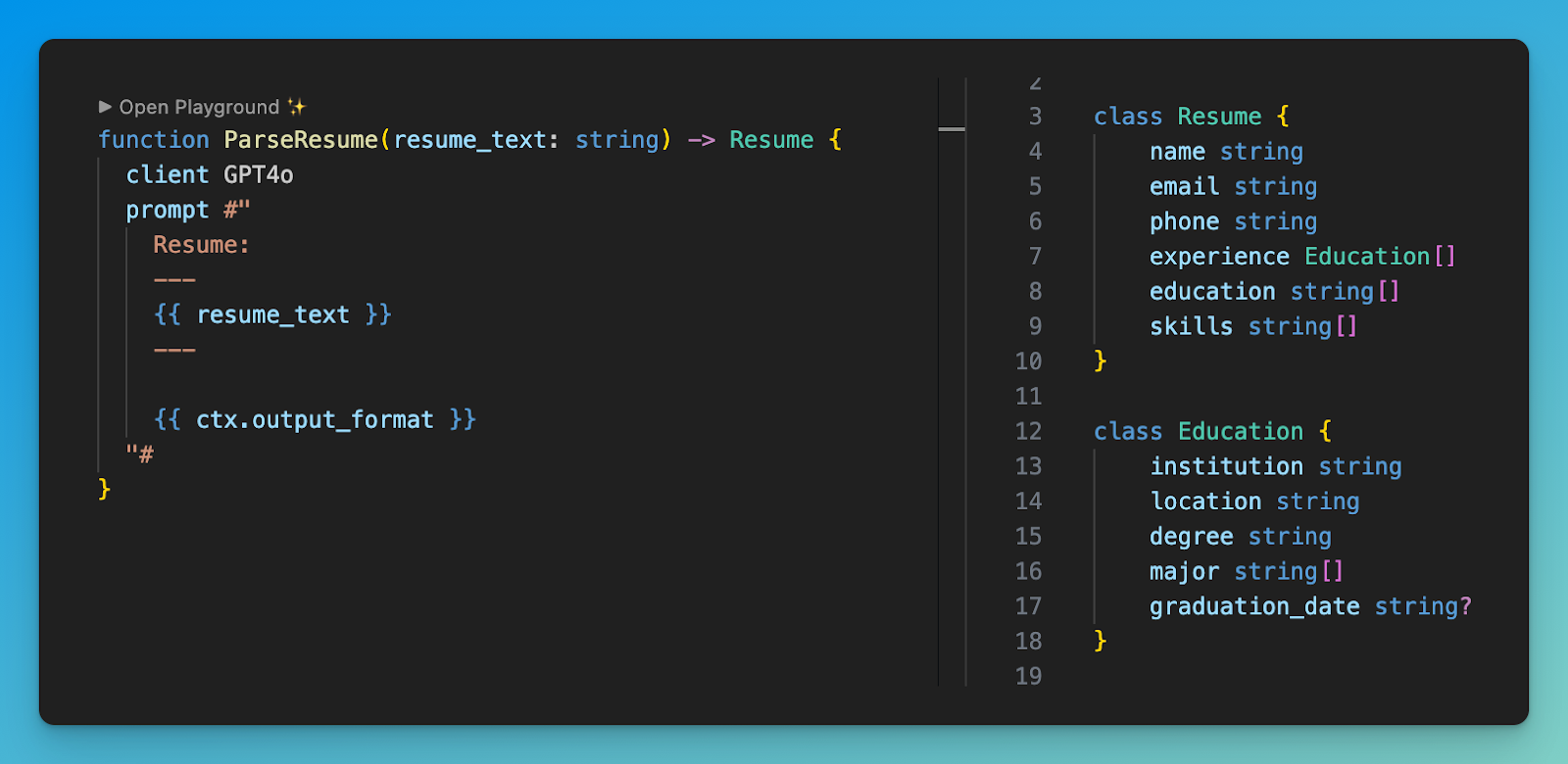
BAML then provides you a type-safe function in the language of your choice (with autocomplete).
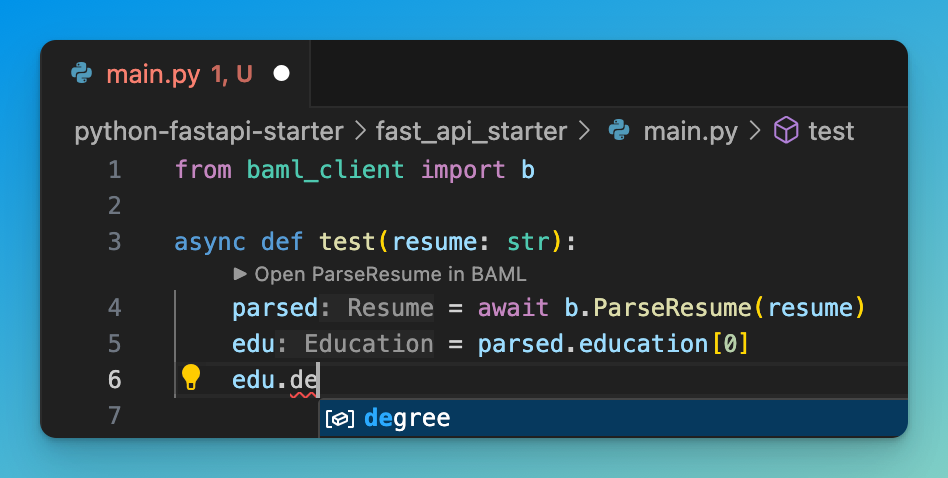
BAML handles everything like parsing, error handling, streaming, and tracing for you. When you call an LLM, you not only get a response, but you can be sure that the response will be exactly what you want. For instance, if you're a company categorizing customer issues into one of 15 categories, BAML ensures the response will come in as a list of categories, just like an API call to traditional software systems.
Who are your users today? Who’s finding the most value in what you’re building with BAML?
BAML is best for users building agents that need to talk to existing software, like your UIs and databases. We have users in many domains, from companies working in healthcare, or analyzing SEC compliance of hedge funds, and some consumer AI chatbots.
BAML changed the way all of our customers think about prompt engineering. They no longer needs long paragraphs trying to explain to the LLM what they want. They define their types, BAML inserts a small type-snippet to the prompt, and parses the response. It just works.
Take one of our customers, Vetrec - which does veterinarian transcript analysis. Vets can be very picky about their notes, and not all of them use the same terminology for everything. On top of that, some vets want bullet point lists, while some want formatted lists in sentence format. Others prefer paragraph form. This leads to writing a multi-step LLM agent. The issue is each step depends on others – and if each step fails just 5% of the time, a 10 step-pipeline fails 40% of the time!
After switching to BAML, Vetrec simplified their pipeline to fewer steps, and delivered each vets’ customized requirements faster. Now, they offload the prompting to the vets, and use BAML to guarantee the structure 100% of the time, so each vet gets exactly what they want, but Vectrec is able to apply the constraints they need to ensure they can save and render the responses into their schemas. This is one thing they were never sure they could do before using BAML.
How do you measure success with BAML? Any specific customer stories you’d like to share with our audience?
I’d say we’ve nailed down three key metrics. The first two are cost and latency. Most people using LLMs may have heard of function calling or JSON mode, but it turns out those aren’t the most optimal methods for getting data. One of our customers switched from function calling and JSON mode schemas to using BAML with OpenAI and Anthropic. They found that their latency dropped from about five minutes to 90 seconds, and they also noticed a significant improvement in quality. This is because our format for communicating with the LLM allows more work to be done in a single call, rather than requiring multiple calls to get the same response.
The last one is a bit odd, but BAML code is pretty. BAML lets you delete all of the code you had to make the prompts work. This likely doesn’t matter when you only have 1-2 LLM calls, but as pipelines get more sophisticated, making it easy to search through your 50 LLM functions and know exactly what model its using, how often its retrying, etc, makes a huge difference in developer productivity.
As a specific example, we have a customer called MuckRock, which handles freedom of information requests. They initially used an old AI pipeline with a standard SVM approach, which was about 20% accurate. After switching to BAML about a year ago, their pipeline’s accuracy improved to around 40% on the first drafts. As they integrated more with our system, they eventually achieved about 95% accuracy. Now, they barely use humans for processing requests, whereas before they needed humans for almost all requests. This not only increased their throughput but also made their accuracy much more consistent for the end users.
Walk us through BAML, what did you make a new programming language?
When we started writing LLM components, one of the key things we realized was that strings have become an essential part of our codebase. I don’t know about you, but I’ve been working with these concatenated strings, f-strings, and other massive constructs that make my prompts almost unreadable. So, we took a different approach. Instead of using LangChain or other systems to assemble prompts, we thought, what if we could write our prompts in their own files, manage them, have autocomplete, and support features like jump-to-definition specifically for prompts? There’s a reason we use markdown not python for docs - designed for it. BAML is designed for prompts.
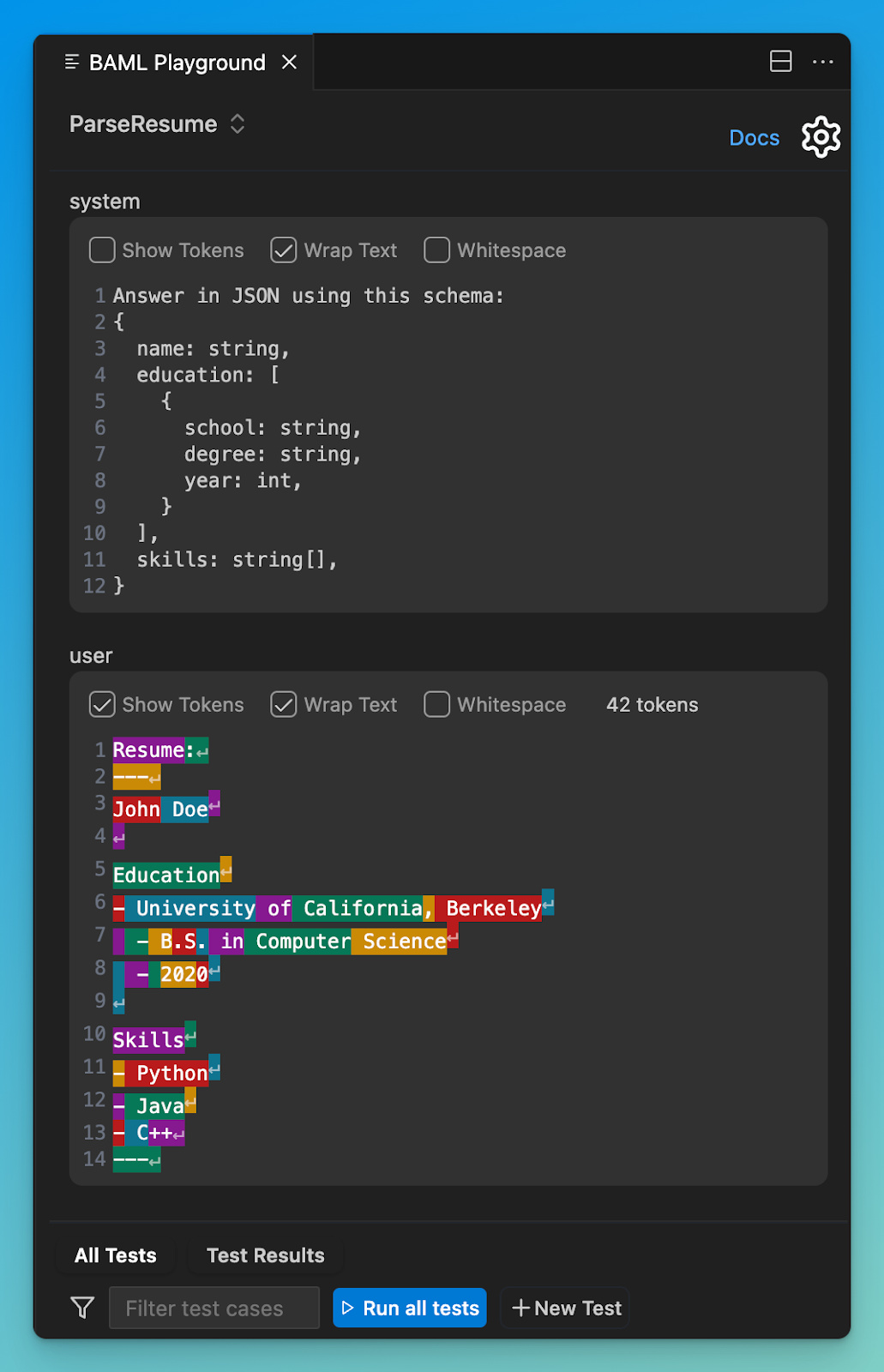
With BAML, we provide many integrations for developers to speed up their iteration process. The most loved feature of BAML is the VSCode Extension. You can see your prompts like a markdown preview and press play to run them without needing any boilerplate test code. Some customers have many if-conditions or loops in their prompts based on user input. Without seeing the final prompt, it becomes incredibly hard to iterate. All of this is open source and completely free.
Our paid offering includes tracing, so you can see all LLM calls in our dashboard, and soon in the VSCode Extension. If a customer has an issue, you can identify it on the dashboard and turn it into a CI/CD test case with just 1 click. This iteration loop is something we aspired to create for most teams. Just like in software, where you write code, write tests, and review the results, you can now see the prompt changes in real time, which changes how you think about the prompt.
The last thing about BAML is that we know learning a new language can be complicated, so BAML is derived from Jinja, a widely used templating language in Python. Tools like Instructor and LangChain also support Jinja, so it’s very easy to migrate.
There are a number of teams focused on reducing hallucinations in the generative AI space - what sets BAML apart? What are you doing differently from others in the space?
A common issue with systems that do JSON parsing, like for function calling, is that when the LLM messes up, they usually retry with another LLM to fix the JSON. It's a pretty common approach, but it means that a function that used to take about 10 seconds now takes around 15 seconds because it’s doubling or tripling its usage rate. BAML handles the data model ourselves and JSON parsing, so we can fix most mistakes from the LLM using algorithms, instead of having to call another LLM. This way, the task only takes milliseconds longer, rather than several extra seconds.
What’s the hardest technical challenge around building BAML?
One of the core distinctions we made with BAML is writing the entire system in Rust. Our whole system is built on Rust because I found it incredibly frustrating to deal with bugs and different implementations across languages like TypeScript and Python when we first started. For instance, if I was using LangChain and there was a bug in the TypeScript version but a feature was available in Python, the implementations were often totally different. This kind of fragmentation is common when trying to implement the same thing in multiple languages.
With BAML, we implemented everything in Rust and then exposed interfaces in Python, TypeScript, Ruby, and other supported languages. This approach was one of the toughest undertakings we’ve tackled as a team because it was new to all of us, but it has helped us maintain consistency across different programming environments.
There’s been an explosion of interest in multimodal AI and image generation. Any compelling use-cases that you’d like to highlight, that BAML is having a high impact on?
We recently worked with a YC company that focuses on image processing for automated website testing, where images are crucial. We helped them add image support to BAML. One of the key things we aimed for was to treat images as just another data type in a prompt. The specific way you feed images into OpenAI, Anthropic, or other providers shouldn’t matter and can be quite confusing when you have to deal with opaque JSON blobs just to pass in image data.
So, when we added multimodal support, we made it straightforward by incorporating types into the BAML language. As long as the type is supported, we handle the hard work of formatting it correctly for whatever LLM you're calling. Currently, we support images and are planning to add audio support in the next week or so. We ensure compatibility with all major providers like OpenAI, Anthropic, Cohere, and Gemini.
Tell us a bit about your team - are you hiring, and what do you look for in prospective members joining the team?

Our team is currently a team of three people, and we also have Anish, our intern for the summer. My co-founder, Aaron, has been a friend for about seven or eight years. He has built some of the largest distributed systems at Amazon during that time, working on things like EC2, core EC2, and watch parties for Prime Video, managing tasks like syncing all that state. In terms of latency and distributed systems, he’s one of the smartest people I’ve had the fortune of working with. Amazing.
Then there’s Sam, someone we met about four or five years earlier. When we asked him to join, it was a tricky decision because he had an offer from OpenAI. One of the core reasons he joined is that when he first used BAML, he felt something that almost every one of our customers had felt—it just felt easy. It changed the way he thought about prompts, and he wanted to help influence that across every other person using the system.
When we hire people, we look for incredibly talented individuals with deep technical expertise, particularly those who can write or are willing to learn Rust, which is a big part of it. If that’s you, reach out over email!
Lastly, talk to us about YC - what are some of the most important benefits you received personally from going through the program this year?
We probably wouldn’t have joined the AI side of the industry, even though our background is so well-suited for it, if it wasn’t for YC. To be honest, YC was almost essential for us to see how big of a problem it was. From my own perspective, working with AI engineers for nearly the last ten years—like hardcore ML PhDs—my experience was always that there was enough tooling out there. During YC, I really saw the need for regular developers who don’t have an ML background to use AI. And I realized there’s a massive gap in tooling.
That would not have happened without YC. The community itself is fantastic. I’ve made some lifelong friends from that batch that I still keep in touch with. I even visited a couple of them in New York last week. It’s hard to overstate the value of YC. If someone is thinking about starting a startup, I highly recommend YC.
Conclusion
To stay up to date on the latest with Boundary, follow them on X and learn more about them at Boundary.
Read our past few Deep Dives below:
If you would like us to ‘Deep Dive’ a founder, team or product launch, please reply to this email ([email protected]) or DM us on Twitter or LinkedIn.