
CV Deep Dive
Today, we’re talking with Aparna Dhinakaran, the Chief Product Officer and co-founder of Arize.
Arize is a leading AI observability and LLM evaluations platform, helping AI developers swiftly identify and resolve issues to improve performance. Founded in 2020 by Aparna and her co-founder and CEO Jason Lopatecki, Arize has become one of the most prominent AI/ML observability platforms in the industry, with thousands of developers and enterprises using it across their ML stack, including Condé Nast, Discord, Etsy and Honeywell, among others.
In April 2023, at the height of the generative AI explosion, Arize launched Phoenix - an open-source library for LLM evaluation and observability. Phoenix is a standalone offering for evaluating and troubleshooting LLM applications that runs inside of a data science notebook environment. Arize previously raised a $38M Series B round in 2022 led by TCV to double down on its platform for enterprise growth.
In this discussion, Aparna shares her thoughts on LLM observability, Phoenix’s importance to AI developers, and their goals for 2024.
Let’s dive in ⚡️
Read time: 8 mins
Our Chat with Aparna 💬
Aparna - welcome to Cerebral Valley! Firstly, share a little bit about your background and what led you to co-found Arize in 2020?
Hey there! My name is Aparna, and I'm one of the founders and the Chief Product Officer here at Arize. I come from a technical background - I was an engineer for many years, and prior to co-founding Arize, I was at Uber working on Michaelangelo, Uber’s ML platform team.
From the past, I’ve had a lot of experience deploying ML models in the real-world. Before LLMs, we had many ML models, and it was really hard to put those models into production. Where typical software was statistical and easy to troubleshoot, ML was much more difficult when it came to interpreting failure modes - we really only found out about issues when a business KPI like revenue was impacted, and it felt like that shouldn’t be the case for a field as important as ML. At the time, we just didn’t have the tools to understand where models were going wrong, and so founding Arize was also about solving a personal pain point.
My co-founder Jason and I got together because he felt the same pain himself. He was in a totally different space working with advertising models, but he witnessed the similar issue of model performance affecting the bottom line. The way we thought about it, models are making billions of dollars of decisions across the technology stack, and if we just have no way of understanding why they're going wrong, we're not putting the best decision makers into our world.
So, we launched Arize in 2020, and have since become the leader in ML observability and now in LLM observability category, given the shift of AI. We have an array of customers from technology giants as well as large packaged goods companies, airlines, credit card transaction companies and more. So, customers not just across tech, but also large enterprises.
As a leader in LLM observability, what does observability mean to you, and what does good observability look like?
To me, good observability is not just about being a red light - green light indicator that surfaces issues with your models - it’s also about providing a toolset that actually gives you the means to troubleshoot and resolve any issues that might come up. In ML, you have this amazing process where your data is what you use to improve your model - so you actually have an ability to not just identify the root cause, but then also use it to improve the KPIs of that model. In this way, observability is much more than just monitoring. Especially on the ML side, it’s about asking ‘how do we ultimately make the model better?’
On the LLM side, what we've been seeing is that it's easy to launch a Twitter demo in a day, but actually launching LLM products into production is extremely hard. For example, companies often want to connect an LLM to their private data, and so a lot of them are using search and retrieval (aka RAG) - but, it’s really difficult to know whether you're actually pulling the right retrieval documents this way. There’s a talk by Yann LeCunn where he discusses whether hallucinations are a bug or a feature, and he concludes that LLMs are actually meant to hallucinate to a degree. So, what happens with RAG is that you’ll often see the LLM hallucinate answers that weren’t in the original documents that were retrieved.
For this reason, in the LLM world, it’s often even harder to get models into production because you have to figure out how to connect the models to your own data and how to evaluate them. In the old world of ML, you were building a classification or ranking model and you simply used the five standard classification or ranking model metrics. Here, you have to evaluate areas like the amount of hallucinations, or clarity of summary, or data repetition - and there’s a lot of nuance because language actually makes evaluations in this space even harder, which means it’s even more likely that companies are not going to be able to do this out of the box.
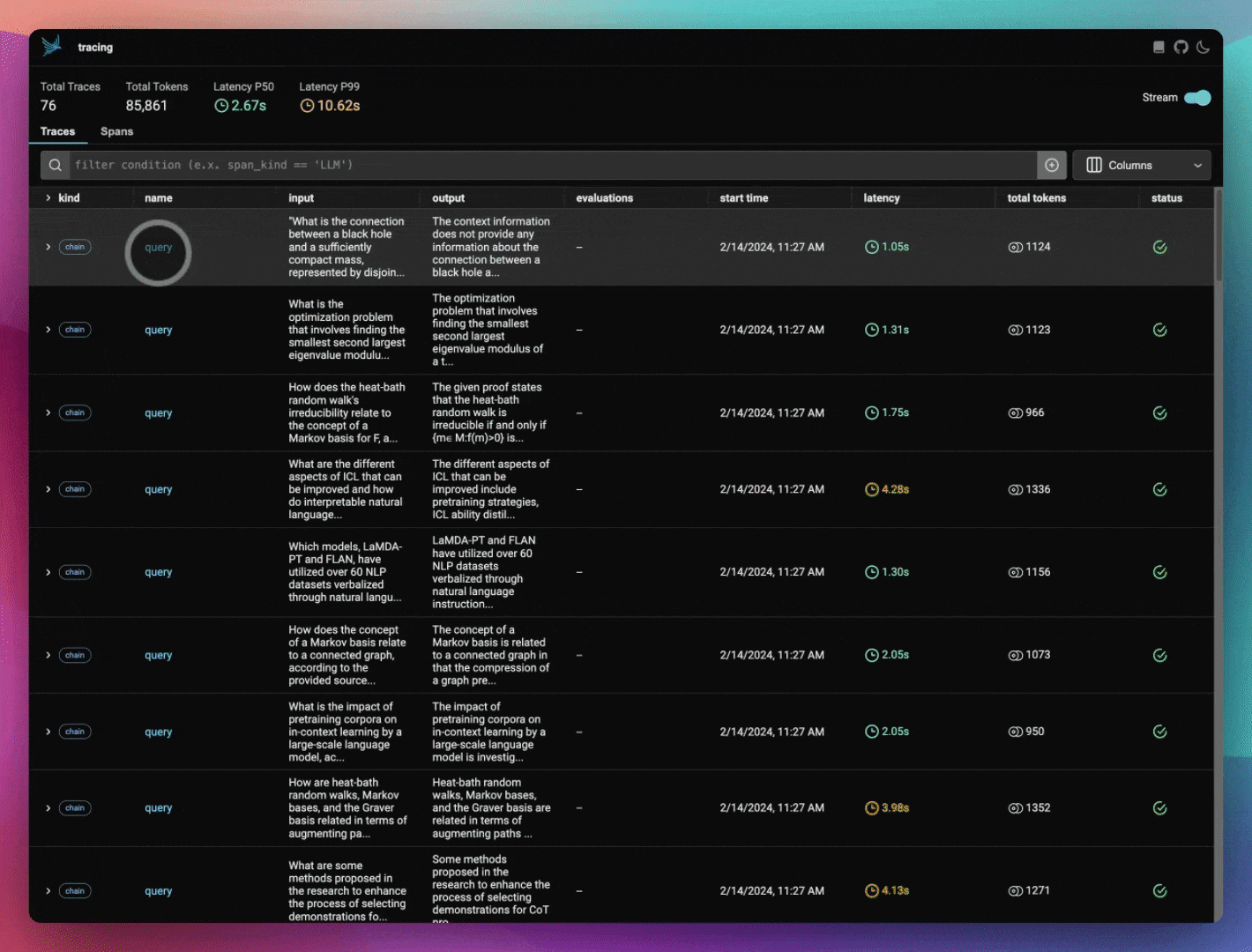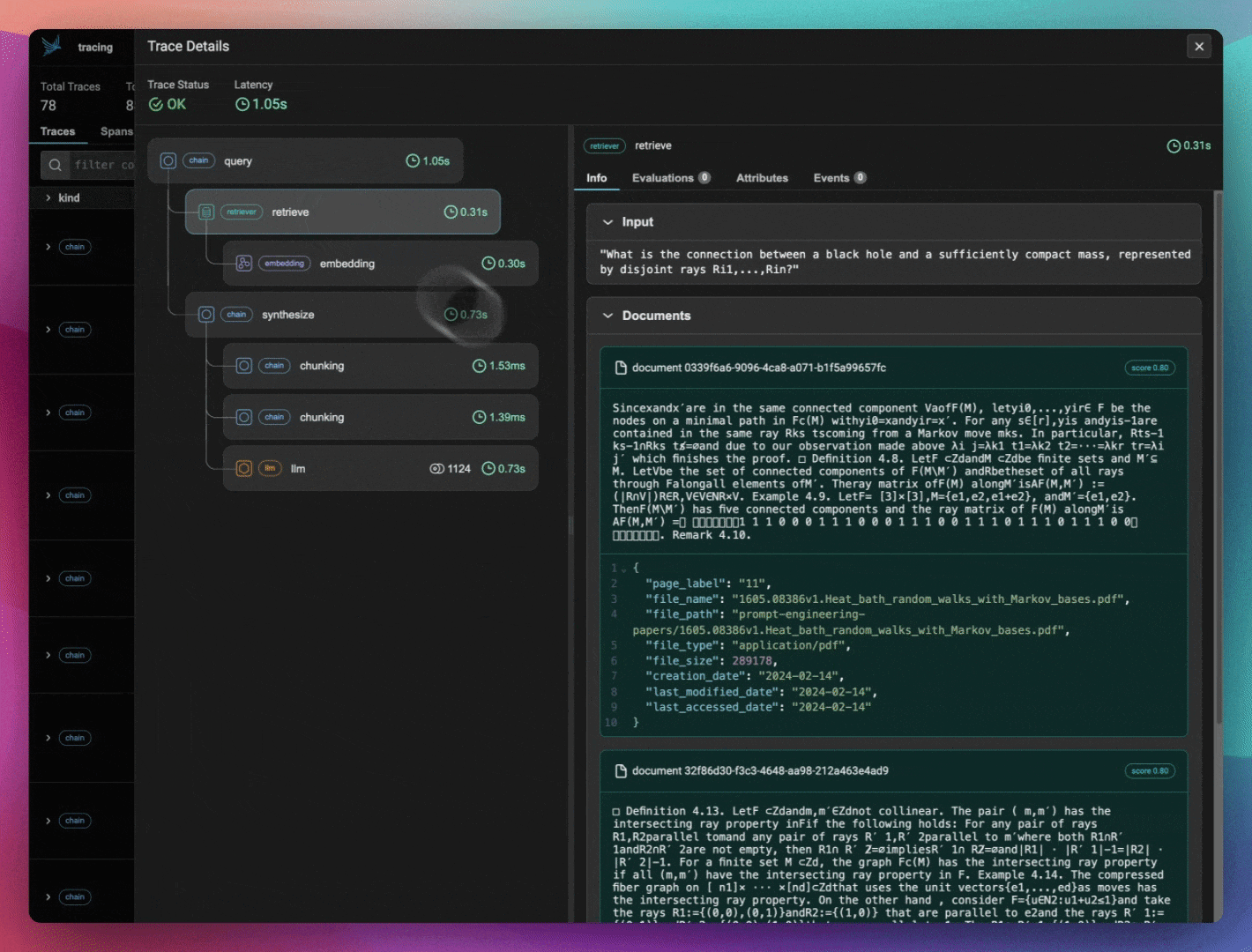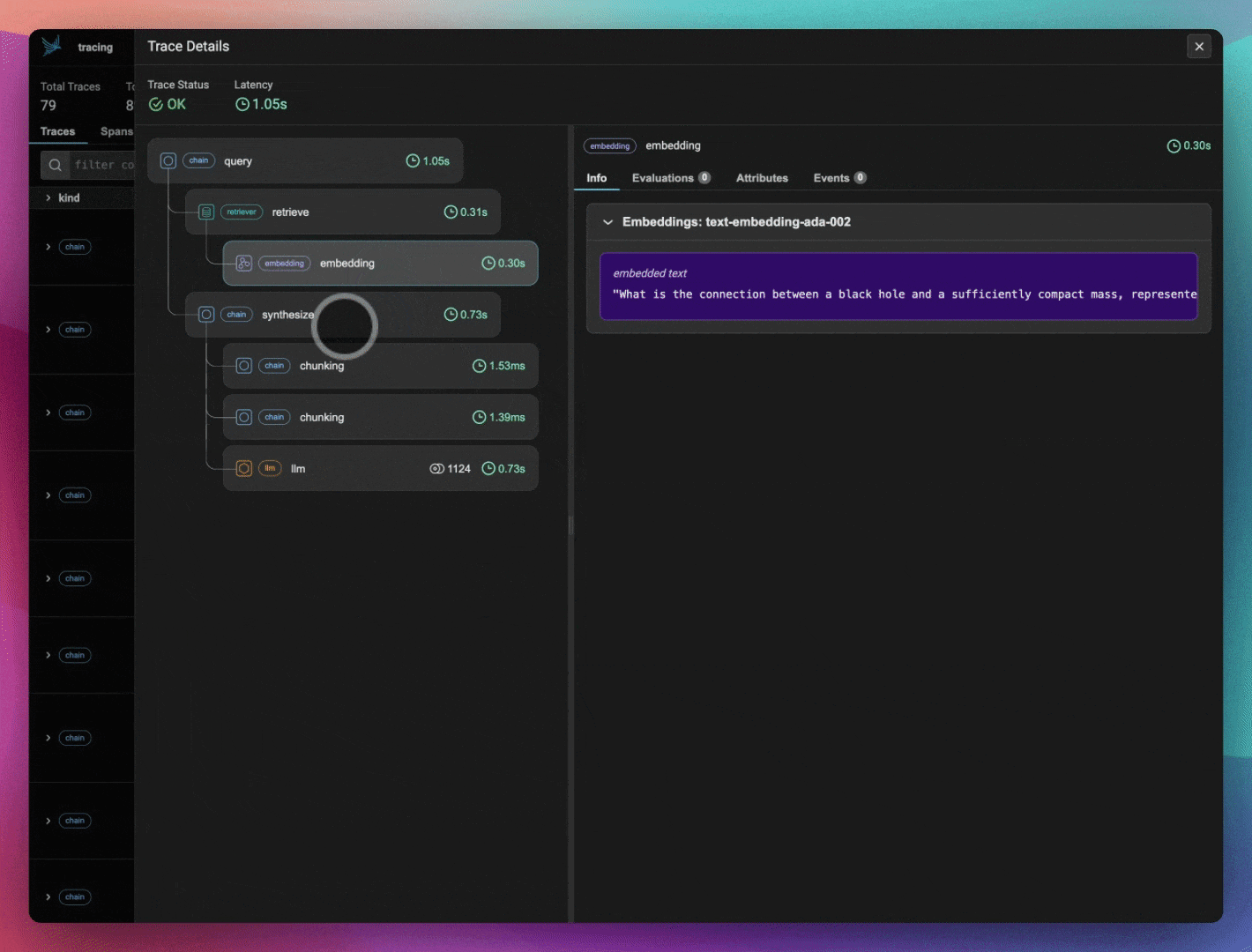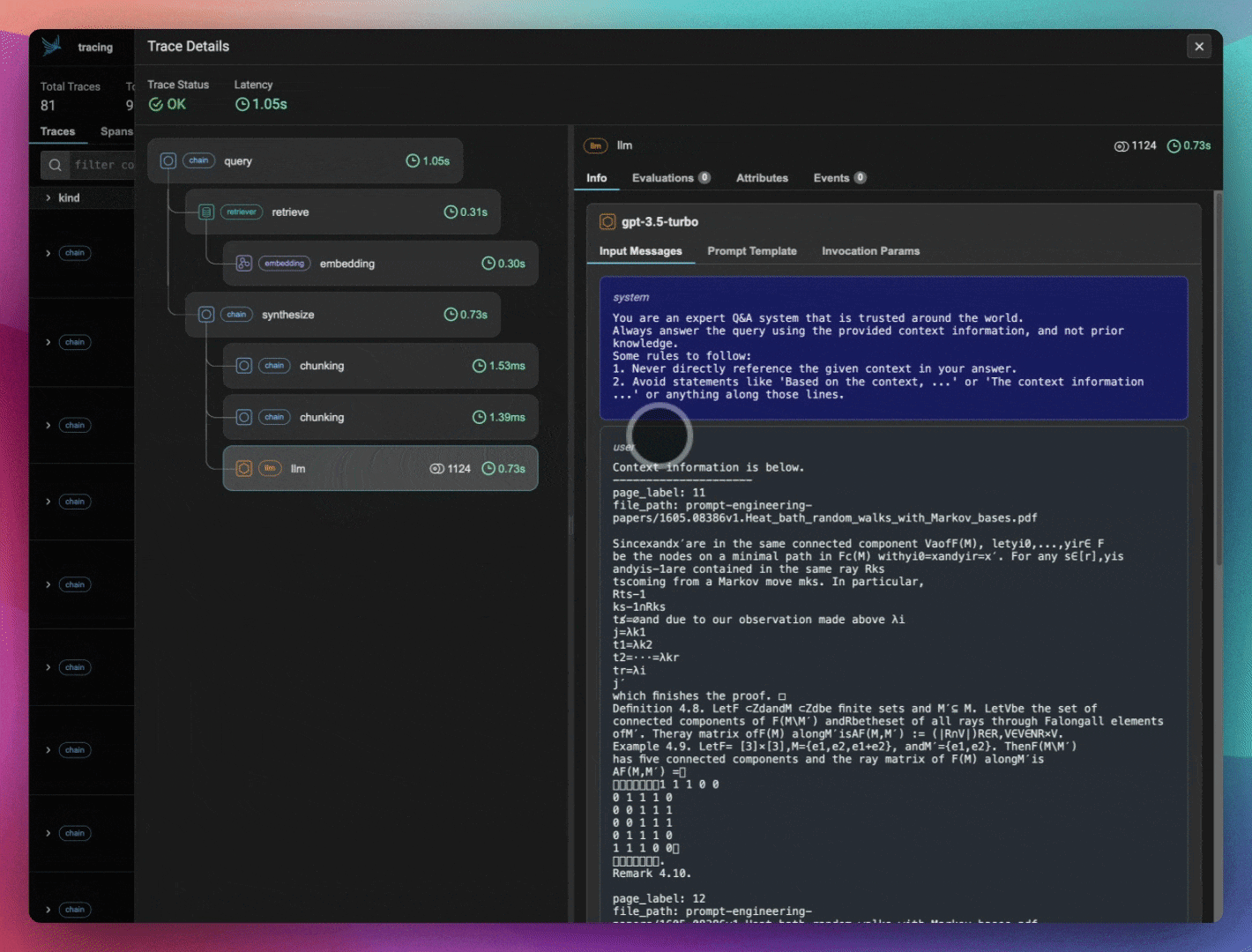
There are various teams working on individual components around evals and observability in the LLM age. How do you ensure that Arize stays competitive amongst the field?
Importantly, I’d say that a lot of use cases we’ve been seeing in production aren’t actually “LLM-only” use cases. An example would be in e-commerce, where a customer goes and interacts with a bot and then are guided towards a product purchase. This is a great use case, because you’re actually driving revenue with LLMs - but in that scenario, we’ve noticed that it’s not just an LLM doing the whole end-to-end flow. There’s actually a ranking model that will rank the products, because the LLM doesn’t have full access to the entire product database just yet.
So you’ll have an ML model working with an LLM side-by-side to achieve an outcome. This is what I think is a major strength of the Arize platform - it’ll be a long time before LLMs transition to taking over all of the use cases that we've had traditional ML do. As we make that transition, we want to have a platform that caters to both - it can help you track the full end-to-end observability of both your ML ranking use-case, or a classification component in there, or even multimodal computer vision. So I think you want something that does that whole spread.
Another thing that’s really great about the Arize ecosystem is our open-source library, Phoenix. With Phoenix, you can check out the code and contribute to it if you want to - we have people that host Phoenix and run it on their own. The reason I bring up Phoenix is that it’s actually designed for that development workflow - specifically, we see a lot of people thinking about evaluations while they're building. Because they do that, Phoenix helps them in their development work - they'll see their full stack trace and understand which calls aren't going well, or are taking the longest, and which evals help them see that. So when they go into production, they have this seamless eval setup where all the collectors, instrumentors and evals are the same.
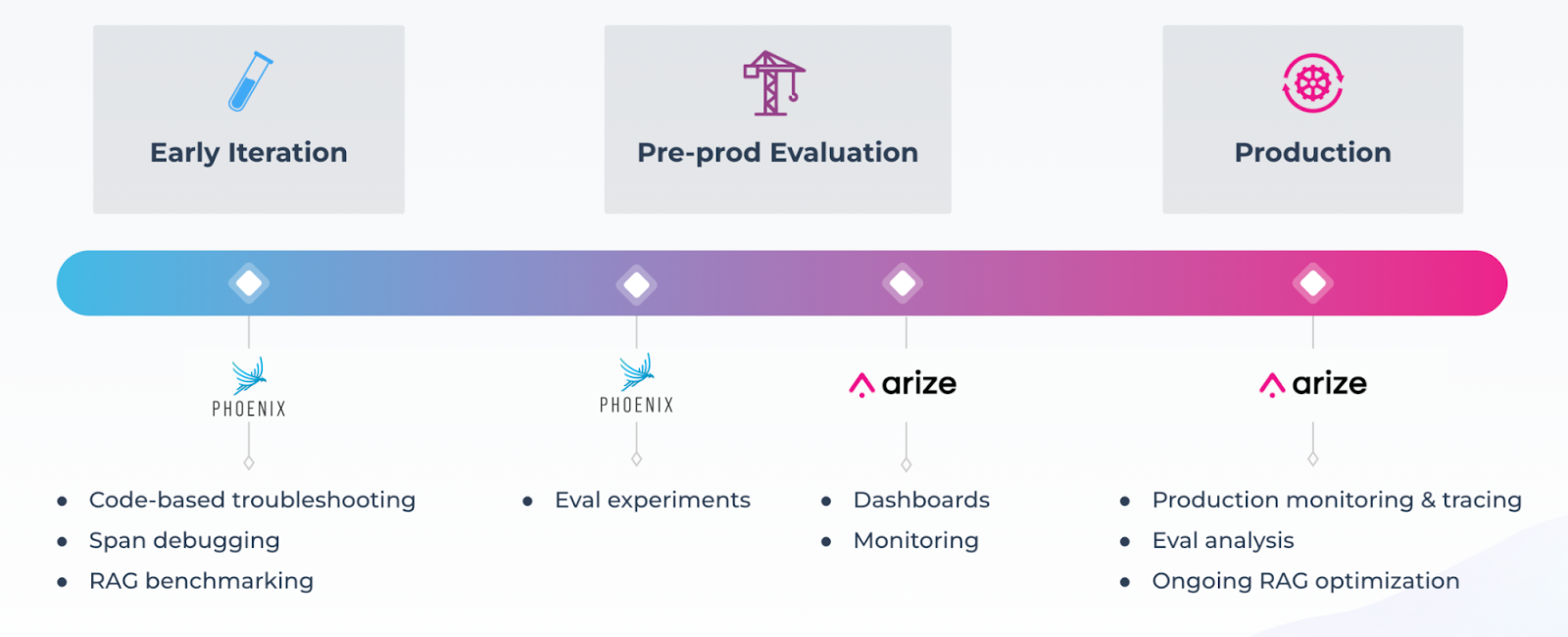
As a result, we’re seeing that people like the idea that they don't need to push all of their data into another platform to see value, and can run a super lightweight experiment in their notebook until it goes into production. That's become almost like our secret weapon of having a tool that helps developers earlier in their journey, and then also throughout the journey of their application.
How would you describe your user base today, in terms of specific job functions? Who is finding the most value in Arize’s platform?
In our “ML 1.0” days, we were focussed on Data Scientists and ML Engineers, which I still think are the majority of our users. Even as we go into enterprises, we’re usually used by the people who are owning the ML models - in some orgs, this is the Data Scientist, who carries it from development to production. In other orgs, there’s almost this handoff from the Data Scientist who owns it in pre-production, to the ML engineer who is responsible for all the KPIs in production. Data scientists and ML engineers are often like swiss army knives who can go between pre-production and owning the model KPIs - so they’ve been our bread and butter.
Additionally, we’re really excited about an emerging group called ‘AI Engineers’, who’ve experienced huge growth with their LLM-powered apps in the past year. These engineers may not have come from an ML background, but they don’t need to - they can just use prompt engineering and know how to connect to a vector database.
We’ve empowered so many engineers to be able to build AI apps without needing to know how to build a model. I'm really excited about this user base that could be this growing set right now. Today, we see them mostly in startups or SMBs, but those could end up being the unicorns of tomorrow. So I’m super excited about this user base.
What does the balance between AI research and productization look like at Arize?
We're deeply passionate about staying on top of and contributing to LLM research. We've actually been releasing research via threads on X with evaluations of what’s been happening in the space. Our customers often ask us questions like “which provider should I be using for this task, and what does your team recommend?” We realized the community could benefit from us sharing the same insights publicly, and it’s great because it then helps us advance our productization.
To that end, we do a lot of rigorous research experiments around evals - for example, the needle in a haystack with Greg Kamradt - where we look at which evals are actually slightly more deterministic, and then release our findings as open research. We always publish our code and our results, and like to give insight into which LLMs we would have used or which are performing better on certain tests.
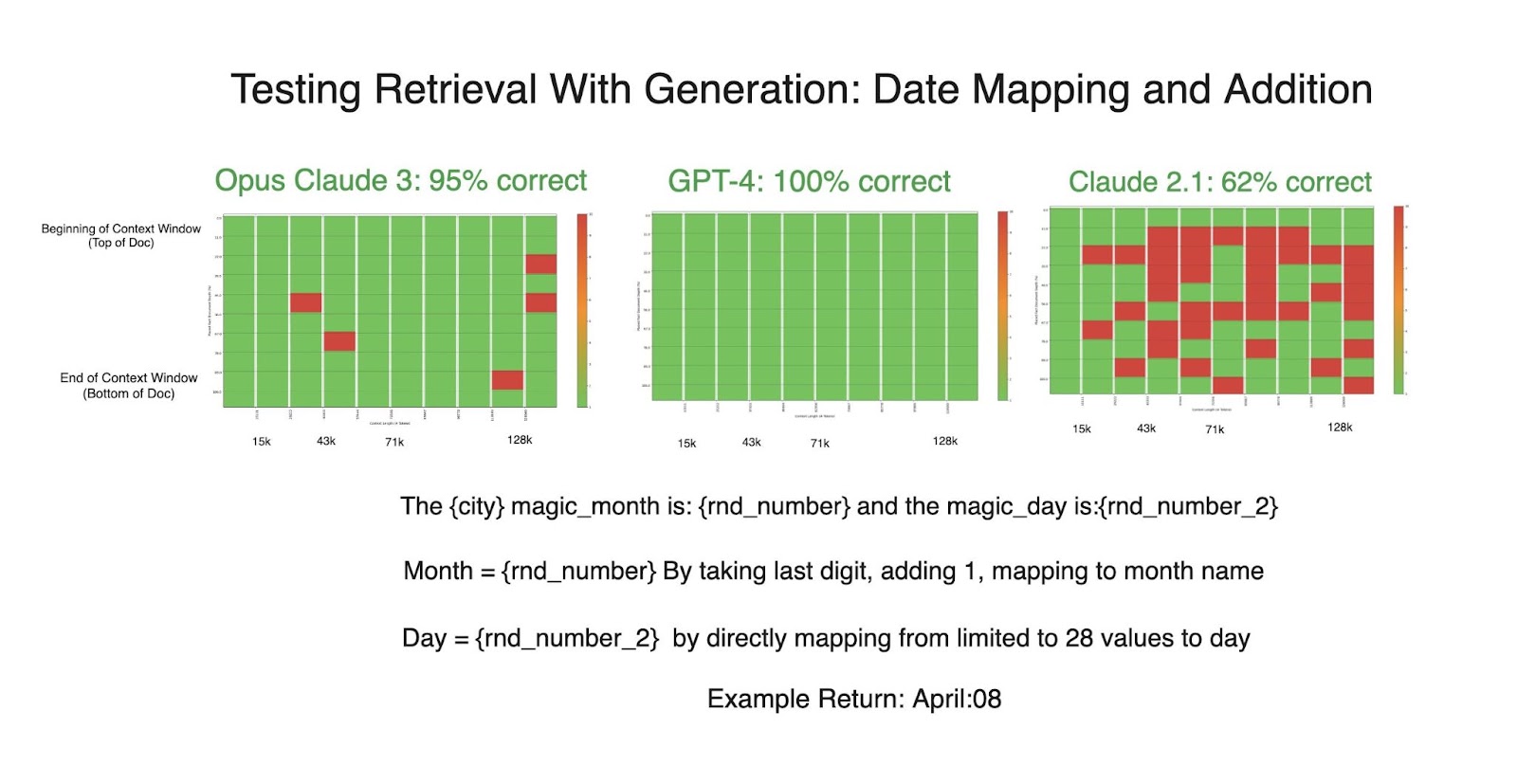
If you look at our Phoenix evaluator, we actually really skew towards classification evals, which is very different from even the OpenAI evaluator in the space. We’ve shared some of our research back with folks, just to be able to say “this is what we’ve seen running this on actual real data”. So, staying on top of the research helps us then come back and build better products and continuously stay ahead of the space overall.
How does the advent of multimodal AI factor into your roadmap over the next 6-12 months?
Definitely! With SoRA, we’re all waiting for people to build apps on that. Again, even in the ML 1.0 space, we’ve had to support a lot of computer vision and audio use cases like object detection and image segmentation. We’ve supported these types of use cases for years, and so we have a foundation already built for that jump to multimodal. Being able to look at the embeddings and understand which types of images or generations are ones that the model does or doesn’t do well on, is absolutely something we’re rolling out soon.
Describe your culture at Arize in 3 words:
Passionate, humble, competitive.
Everyone on our team loves staying on top of this space - it’s not like something where it feels like homework. Everyone is humble - there are folks who could totally have a chip on their shoulder but don’t, which contributes to a learning environment. And we’re all go-getters - we have a “do, not say” culture which we’re really proud of because it’s helped us build with immense velocity and consistently serve our customers.
Conclusion
Read our past few Deep Dives below:
If you would like us to ‘Deep Dive’ a founder, team or product launch, please reply to this email ([email protected]) or DM us on Twitter or LinkedIn.