
CV Deep Dive
Today, we’re talking with Emmanuel Turlay, founder and CEO of Airtrain AI.
Airtrain helps AI engineers refine their datasets to ensure high data quality for training, fine-tuning, and evaluation. The platform offers powerful tools like auto-clustering, AI classification, data exploration, and LLM fine-tuning features that enable users to curate and optimize their datasets, ultimately leading to better-performing models. Airtrain serves a range of customers, from early-stage startups to large enterprises, including well-known global organizations.
With a background in particle physics research at CERN, Emmanuel transitioned into the tech industry 14 years ago, contributing to significant projects at companies like Instacart and Cruise, where he built and scaled machine learning infrastructure. In 2022, he founded Airtrain AI to focus on the emerging GenAI community with a data platform designed to improve the quality of unstructured data for AI development.
Airtrain (YC S22) raised a $3.2M seed round in 2022, led by Race Capital with participation from Y Combinator, Soma Capital, Pioneer Fund, Oliver Cameron, Leonis Capital, Jeremy Stanley, Brandon Leonardo, and Fundament.
In this conversation, Emmanuel shares the story behind Airtrain, research vs. startups, breaks down the AI data competitive landscape, and more.
Let’s dive in ⚡️
Read time: 8 mins
Our Chat with Emmanuel 💬
Emmanuel - welcome to Cerebral Valley! Let’s start with some background on yourself and what led you to start Airtrain?
Thanks for having me! I’m Emmanuel, the founder and CEO of Airtrain AI. My background is a bit unusual—I started my career in academia, doing particle physics research at CERN about 15 years ago. After about four or five years in academia, I transitioned into tech, working in various startups in Europe before moving to the U.S. ten years ago. I joined Instacart, where I spent four years building systems around order processing, payments, and ML ops, including orchestration of training pipelines.
In 2018, I moved to Cruise, the self-driving car company, where I started the ML platform team. Over the next four years, we built platforms to accelerate machine learning development, including orchestration of training pipelines, lineage tracking, and visualization tools. Then, in 2022, I left Cruise to start my own company. Initially, we launched a product called Sematic, an open-source orchestrator for ML pipelines. However, about a year ago, we pivoted to Airtrain to focus on the emerging GenAI community and provide higher-level tools for this new wave of AI engineers.
You have a really intense background in research, was it difficult to switch to the world of building product?
I really loved research because I got to work with some of the best physicists in the field at CERN. One thing I appreciated about academia, especially in particle physics, was the time we had to do deep research. We weren’t pressured by market trends or economic incentives; we had the time to do things thoroughly. For example, the LHC was supposed to launch in 2001, but during my PhD around 2009, it still hadn’t launched because scientists kept asking for more time to ensure everything was done correctly.
What I didn’t like about academia was, ironically, the slow pace. In physics, everything has to be approved by committees and thousands of scientists, which makes sense for thoroughness and correctness, but it slows things down. What I love about startups is the ability to make decisions quickly—you can decide something in the morning, push it to production in the afternoon, and measure results the next day. I really enjoy the fast-paced environment of tech startups.
How would you describe Airtrain to an uninitiated AI developer? And when and why would someone use Airtrain?
We started about a year ago focusing on Eval because the space was still early, and we weren’t sure where it was headed. Many people told us they didn’t know how to choose models or compare the same model with different prompts, so our first product was a batch eval tool. But we’ve come a long way since then, working on fine-tuning models and realizing that data quality is at the core of most problems. This has always been true, whether in traditional machine learning during my time at Cruise, or in the new GenAI space—the quality of your data directly impacts the quality of your models and evaluation metrics.
Now, we’ve built a data platform for unstructured data to help people curate datasets for training, fine-tuning, evaluation, or simply explore data. Our core product is a data exploration platform where users can upload text-based datasets. Out of the box, they get features like auto-clustering, AI classification, and labeling on top of the usual search and curation capabilities. We help users start with a large, potentially noisy dataset and refine it to the highest quality possible because we’ve seen that the quality of your model is closely tied to the quality of your input data. So, our focus is on improving data quality for eval, training, and exploration.
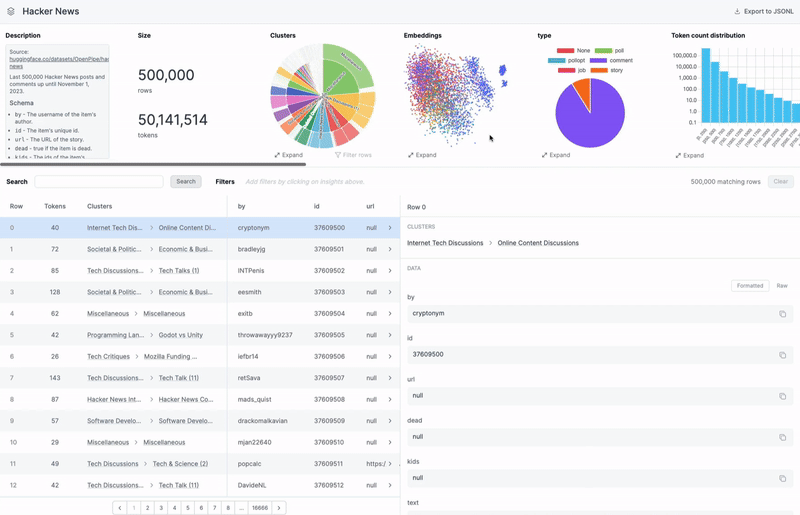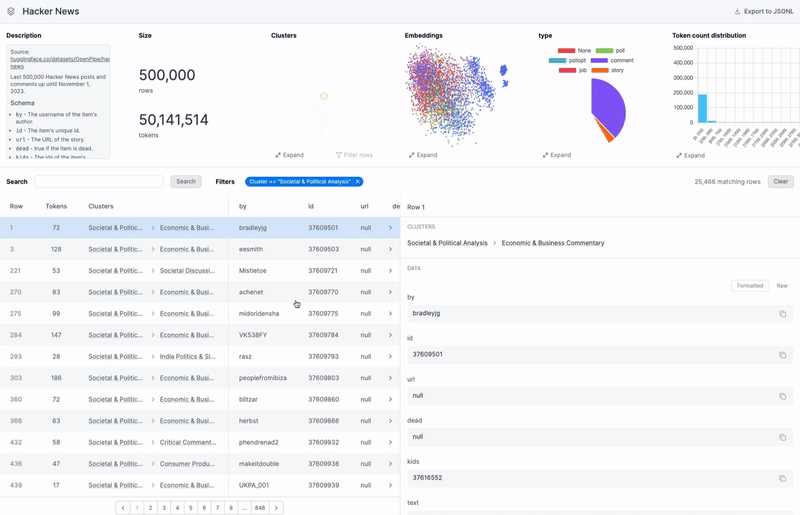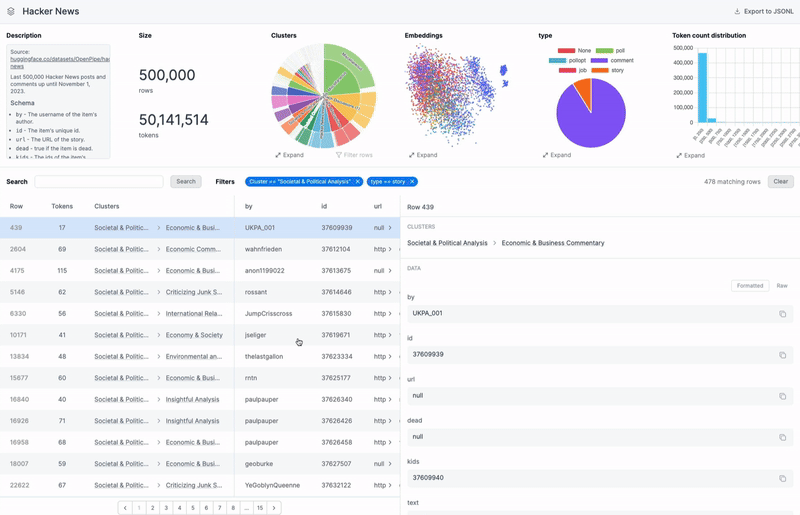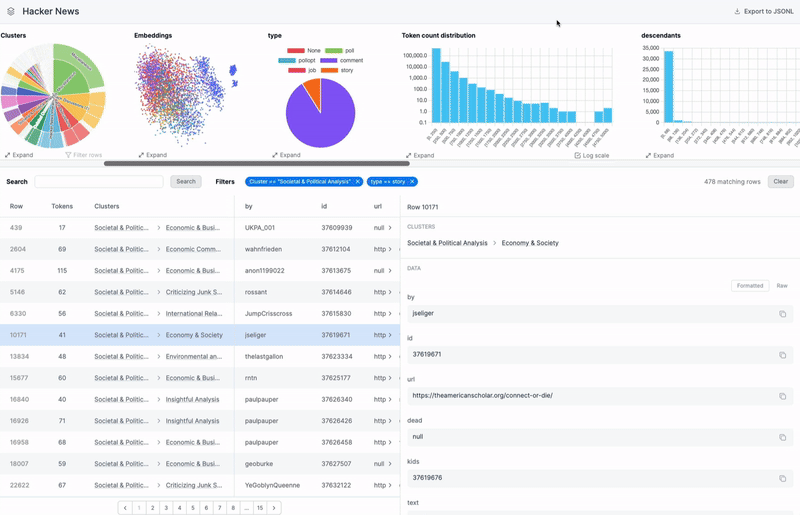
Can you dive deeper into how an AI engineer uses Airtrain to ensure a dataset is of high quality?
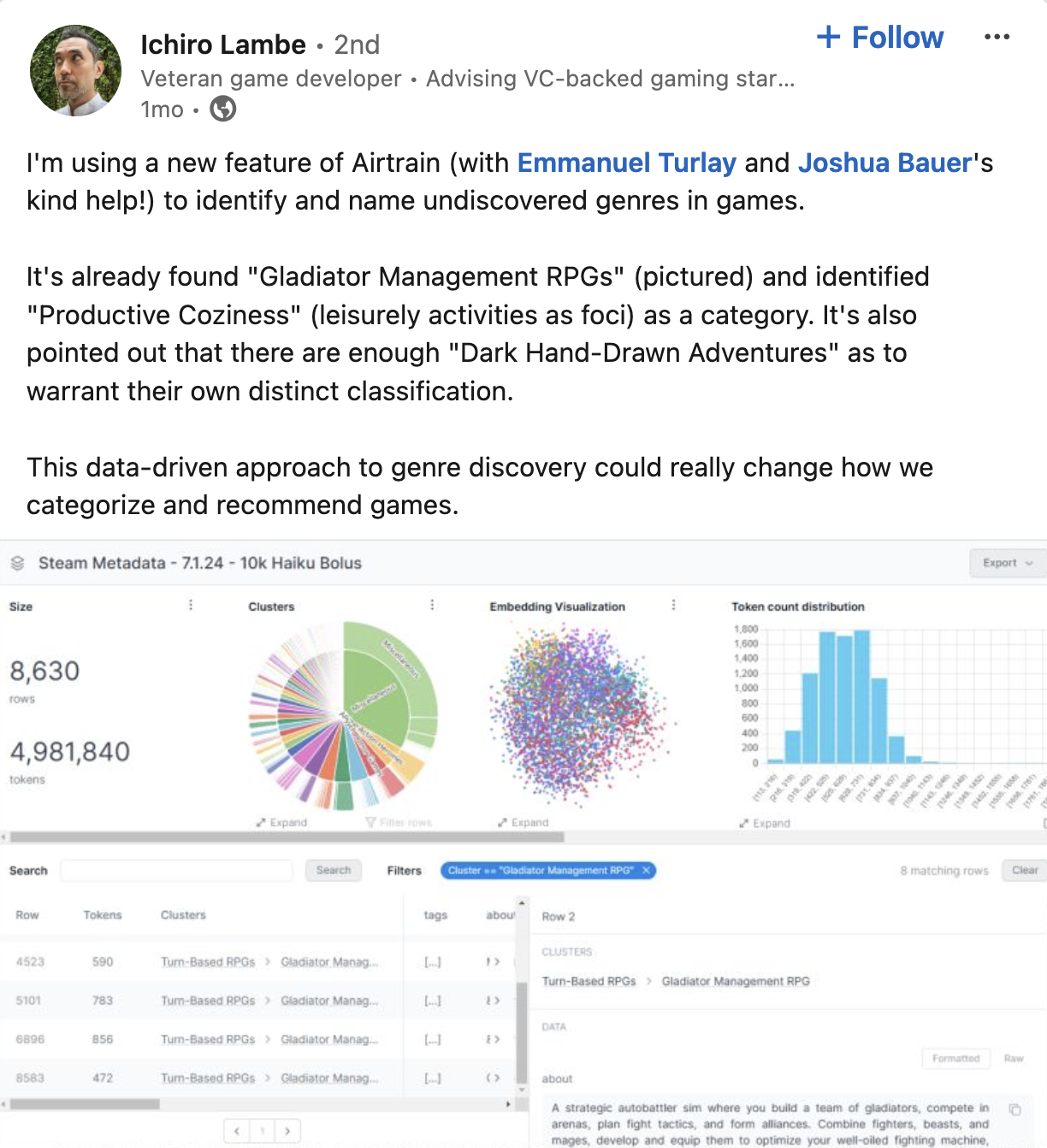
The first feature we introduced when launching our dataset product is auto-clustering. When you upload your dataset, our system automatically finds and labels semantic clusters within the data. After a few minutes of ingestion, you can browse your dataset by labeled clusters such as “math questions”, “chemistry topics”, or “international politics”, without needing to provide any information upfront. This allows you to discover patterns or niches you weren’t aware of. This feature also helps you assess the balance of your dataset. For instance, you can identify if certain types of data are overrepresented or underrepresented, which is crucial when creating a training dataset that should resemble your production data as closely as possible.
We also assist in identifying duplicate information—a common issue where overrepresented data can cause a model to overfit, leading to repetitive or biased outputs in production. For example, we’ve just released Fineweb-Edu-Fortified, an open dataset based on the FineWeb-Edu dataset, where we found that 70% of the data was duplicated. This not only wastes compute resources but also risks model overfitting. So, we focus on helping our customers find and resolve these issues to improve the quality of their datasets.
Once they have this refined dataset, they can use it to fine-tune LLMs on Airtrain, such as Mistral 7B, LLaMA 3, or Gemini 2. After fine-tuning, we also assist them in evaluating the performance of these models, comparing them against off-the-shelf models like GPT-4. Many users want to replace larger proprietary models with smaller, more cost-effective options, and we help them assess whether their fine-tuned models meet their needs. But again, this evaluation comes after we’ve helped them ensure the highest possible data quality, which is our primary focus.
Can you take us under the hood a bit and tell us how this works technically?
Absolutely. Let me start with our compute infrastructure. Before we built Airtrain, we developed an open-source orchestrator for ML called Sematic, optimized for distributed and long-running compute tasks with built-in fault tolerance, running on Kubernetes. This orchestrator is the backbone of Airtrain, powering our pipelines for tasks like eval, fine-tuning, and data ingestion.
For clustering, we generate embeddings for your data and apply techniques like HDBSCAN to cluster these embeddings. The challenge is that while these algorithms can identify clusters, they don't label them. So, we sample rows from each cluster and feed them to an LLM to generate a high-level theme for the cluster. We do this twice—first to create base clusters, which are the most granular clusters and a second time to generate meta-clusters. Our visualization, particularly the double pie chart, shows this hierarchy.
It's important to note that this process is non-deterministic, meaning if you rerun the algorithm on the same dataset, the clusters and their names might be similar but not identical. We're also launching an AI classification and labeling feature where users can specify the classes they want to see, and we'll classify the content accordingly. We use a mix of LLMs and proprietary algorithms for this, balancing the power of LLMs with cost efficiency by seeding classifications with LLMs and then expanding using embeddings and other techniques.
Who exactly are Airtrain's users?
Our customers are primarily AI teams across a range of company sizes, from early-stage startups—often YC companies—looking to move quickly with fine-tuning or evaluation, all the way to large tech unicorns. For example, we've helped one e-commerce unicorn fine-tune a model to replace a costly internal GPT system. We are super excited to help AI teams of all sizes adopt GenAI faster and with more confidence and higher quality.
This space—data evaluation, data cleansing, data labeling, LLM evaluations—is super hot right now. Could you help us understand the competitive landscape? What sets Airtrain apart from your competitors from a developer perspective?
It's a very lively ecosystem, especially since November 2022 when OpenAI launched ChatGPT. Since then, hundreds, if not thousands, of startups have entered the field. Evaluation (Eval) remains the biggest challenge today. However, the problem with Eval is that many companies prefer to build their own tools and systems. For instance, a lot of people still do their evaluations manually, with just a few dozen prompts. This is especially true for those developing AI apps, chatbots, or retrieval-augmented generation (RAG) products. On the other hand, companies building models have more rigorous and thoughtful evaluation processes.
The Eval space is tough to penetrate because best practices haven't crystallized yet. Every month, a new high-quality model emerges, disrupting the landscape. Many companies are offering online Eval tools, focusing on logging LLM traces and providing metrics like thumbs up/thumbs down, safety, or toxicity evaluations. We chose not to pursue this because our strength lies in offline compute, a space where we focus on batch Eval. Our platform allows users to upload a dataset, select models, run inference, and evaluate metrics in a UI.
When we looked at fine-tuning, it seemed like a promising area, especially as a cost-effective alternative to using large models. However, as models become cheaper and more efficient, the argument for fine-tuning as a cost-saving alternative is losing some ground. I believe fine-tuning will still be necessary for certain specialized models, but it may not become a mainstream practice across the industry.
This realization led us to focus more on data-centric products. Data quality is crucial, no matter what you do—whether it's for analytics, evaluation, training from scratch, or fine-tuning. Many companies, including legacy enterprises, are sitting on vast amounts of unstructured data like PDFs, invoices, legal documents, and meeting notes. They now want to label, classify, and extract information from these datasets, which is increasingly possible thanks to LLMs. This shift toward understanding and leveraging unstructured data is where I see the AI dev tool industry heading, and it's a more concrete and impactful use case than typical chatbot applications.
Where do you see Airtrain going in the next phase? You currently support only text-based data. Do you have a strategy on expanding into multimodal AI?
While we're not currently focused on structured data extraction, our primary aim is data exploration and curation. We may consider adding data extraction features in the future, but right now, we're more geared towards helping data science teams with tasks like topic modeling through our auto-clustering feature. For example, gaming platforms with large datasets of user-generated content might use our platform to identify trends or clusters within that data. We're also about to launch an AI labeling feature, which will further support the creation of high-quality datasets.
As for multimodal AI, we had to start somewhere, so we began with text. However, our infrastructure is built around embeddings, meaning that once data—whether text or images—is converted into embeddings, we can apply all our existing logic like auto-clustering, labeling, and classification. While we haven't implemented support for images yet, it's something we're considering, especially as our roadmap is heavily influenced by customer feedback. We're a small team, so we have to prioritize carefully, but expanding into multimodal capabilities is definitely on our radar.

Tell us about the team at Airtrain? Are you hiring, and what do you look for in prospective team members?
We’re a team of five. Three of us were co-workers at Cruise, where we were already building ML infrastructure and handling large-scale compute, so we bring a lot of context from that experience. We also have another engineer based in Paris and one person in marketing who helps us get our message out there.
Our culture is very mature and focused on fostering passion for the work we’re doing. We’re all senior engineers, and we prioritize creating an environment where everyone can reach their "zone of genius." This means allowing each team member to work in a way that suits them best, so they can truly enjoy what they do and produce their best work. We emphasize being nice and respectful to each other while also striving for excellence in everything we do.
As a startup, we sometimes have to make quick decisions and take shortcuts, but we always aim to do the right thing and contribute positively to the community—like with the open Fineweb-Edu-Fortified dataset we launched last week on Hugging Face. While we’re not currently hiring, our culture is very inclusive, and we encourage everyone to learn and grow by exploring areas they might be less familiar with.
That’s a high-caliber team! Last question, what’s the long-term, grandiose vision for Airtrain?
If we’re talking about a ten-year vision, the goal is to democratize access to infrastructure. This is something we focused on at Cruise when we were part of the platform team. Our customers were ML and data science teams who were experts in their fields but didn’t necessarily have the expertise to navigate complex cloud infrastructure. We had to build products that made it extremely easy for them to access things like GPU clusters, visualize job outputs, or debug pipelines.
With Airtrain, we want to create a high-level, low-code/no-code platform that makes it simple for data scientists, ML engineers, and AI engineers to tap into powerful compute resources without needing to know the ins and outs of cloud infrastructure. That’s the long-term vision.
In the short term, we’re focused on the data space because there’s a lot of hype around AI right now. Larger companies, especially in the enterprise space, are caught between the pressure from their boards to jump on the AI bandwagon and the need to proceed cautiously to avoid risks. Many are hesitant to launch AI initiatives without ensuring safety and reliability.
We aim to build confidence among these companies so they can explore AI without diving into high-risk use cases like chatbots. Instead, we’re focusing on safer applications, like extracting insights from unstructured data, which can be applied broadly across legacy enterprise businesses. Our goal is to help these companies enter the AI space safely, bridging the gap between the cutting-edge companies pushing new boundaries every week and the more traditional businesses that need to approach AI with caution.
Conclusion
To stay up to date on the latest with Airtrain, learn more about them here.
Read our past few Deep Dives below:
If you would like us to ‘Deep Dive’ a founder, team or product launch, please reply to this email ([email protected]) or DM us on Twitter or LinkedIn.