
CV Deep Dive
Today, we’re talking with J-D Allegrucci, VP of Engineering at Rain AI, and Ross Pantone, Founding Engineer and Head of Product.
Rain AI is innovating AI chip architecture with a focus on inference for next-gen AI agents, reasoning models, and AGI. With reasoning and agentic applications growing in popularity and models emerging with more parameters and context, the demand for efficient hardware solutions is only increasing. The company is developing memory-centric hardware using digital compute-in-memory (dCIM) technology, designed to minimize data movement and maximize efficiency for massive AI workloads. With roots in research and significant milestones like demonstrating working silicon in TSMC’s advanced process nodes, Rain AI is making steady progress toward commercializing its unique AI hardware approach.
Key Takeaways:
Specialization in Next-gen Agents and Reasoning Models: Rain AI focuses on the largest and most demanding models, prioritizing efficiency and scalability on these workloads instead of chatbots.
Innovative CIM Architecture: Compute-in-memory integrates computation within memory, significantly reducing energy consumption and improving performance compared to GPUs.
A New Chapter: With J-D Allegrucci, a semiconductor veteran from Apple, joining as VP of engineering- and among other recent senior veteran hires - Rain AI has transitioned from a research-oriented startup to a disciplined chip production company focused on execution and delivery.
Rain AI raised a seed round in 2018 led by OpenAI CEO Sam Altman, and a $25 million Series A in 2022. The company has raised a total of $53M. Other investors include Y Combinator, Jaan Tallinn, Airbus Ventures, Grep VC, and Liquid 2 Ventures.
In this conversation, Ross and J-D share the evolution of Rain AI’s research, the unique compute challenges of next-gen AI applications, and the rapidly developing competitive landscape of AI Inference chips.
Let’s dive in ⚡️
Read time: 8 mins
Our Chat with Ross and J-D 💬
Hey Ross and J-D - welcome to Cerebral Valley! To kick things off, could you both introduce yourselves and give a bit of background on Rain AI?
Ross:
Hey! I’m Ross, founding engineer and head of product at Rain AI. My background is in math and computer science. I got into AI in 2015 when everyone was beginning to adopt GPUs. Even then, I remember spending weeks trying to get my hands on the latest NVIDIA Pascal GPUs to run what are now considered tiny models. As I dug into the hardware details, I saw that while GPUs work well, there’s a huge opportunity for further optimization if we perform deep hardware-software co-design—tailoring the hardware for these AI models down to the transistor level. That idea really intrigued me.
To give a quick overview: Rain AI is a chip startup headquartered in Silicon Valley. We’ve got an office here in San Francisco, one in Sunnyvale, and a co-working space in SoCal to meet candidate demand down there. We’re building hardware and software specifically for massive inference and post-training workloads, unlocking advanced agents, reasoning, and eventually AGI.
Our mission is straightforward but ambitious: we want to be the first hardware vendor to power AGI. If you look at where compute is today, hyperscalers are constructing enormous data centers that eat up gigawatts of power—just massive facilities that didn’t even seem possible a few years back. The cost is enormous, tens of billions in CapEx. Our focus is on enabling more intelligence per dollar and per watt for the largest models. And we do it by going back to first principles, reducing data movement at every level of the hardware stack, down to the transistor level.
J-D, you joined more recently. Could you share your background and what brought you to Rain AI?
J-D:
Sure thing. My name is J-D, and I’ve basically spent my entire career in semiconductors. Before Rain AI, I was at Apple for 17 years. I joined Apple right when they decided to get into chip design—maybe 20 people at the start—and we aimed to build the SOCs for the iPhone.
Early on, I owned SOC design and integration for the iPhone, and eventually, I led a team of nearly a thousand engineers that handled design verification for all the IPs, not just for phones but also iPads, watches, Macs. Over time, we developed a methodology at Apple that let us deliver chips methodically, with consistent high quality, and crucially, never miss a tape-out deadline. You know Apple: you can’t delay an iPhone launch.
When I was wrapping up at Apple, I wanted to move into the AI space. Internally, that’s slower at a big company. Outside, Rain AI caught my eye. They had something truly interesting, a strong management team, and all the ingredients to do something exciting. So I’m bringing my semiconductor know-how to Rain AI. Together with the rest of the team, I think we can achieve what we’ve set out to do.
Can you tell me about the early days of Rain AI?
Ross:
It has been a journey. Early on, Rain AI was just a handful of us in a small research setting, focusing on reducing data movement and improving energy efficiency for core AI operations—especially matrix multiplication, which underlies pretty much all modern AI models like GPT-4o, o1, Llama, Claude, and so forth. We viewed improving the efficiency of matrix multiplication as key to developing a high-performance architecture. We tried a bunch of techniques over the first few years. Since we had that R&D freedom, we really honed in on what would yield the best results for AI workloads.
In 2022, we felt confident we’d found the right recipe. We raised our Series A, scaled up engineering, and started multiple chip projects in advanced TSMC nodes to prove out our core technology. We taped out these two chips recently. . With the core building blocks derisked, we are now laser-focused on scaling up our architecture to support the largest models at high performance and efficiency.
So what exactly is compute-in-memory (CIM)?
J-D:
When you do matrix multiplication, you have weights (coefficients) and input vectors. Normally, you store weights in registers, move them to a processing unit, combine them with the input vectors, and store the outputs elsewhere. It’s a lot of data moving around—lots of power spent shifting data.
With CIM, we bring coefficients right into compute units inside the memory. That way, we’re minimizing data movement fundamentally. Less data movement means less power, and because everything’s close—the coefficients, vectors, and compute logic— it’s far more efficient. Essentially, we’re merging the memory and compute so the heavy lifting happens right where the data already is.
Let’s talk about the competitive landscape. You’ve got big chip incumbents plus various startups. How does Rain AI stand out, both in terms of product focus and technical approach?
Ross:
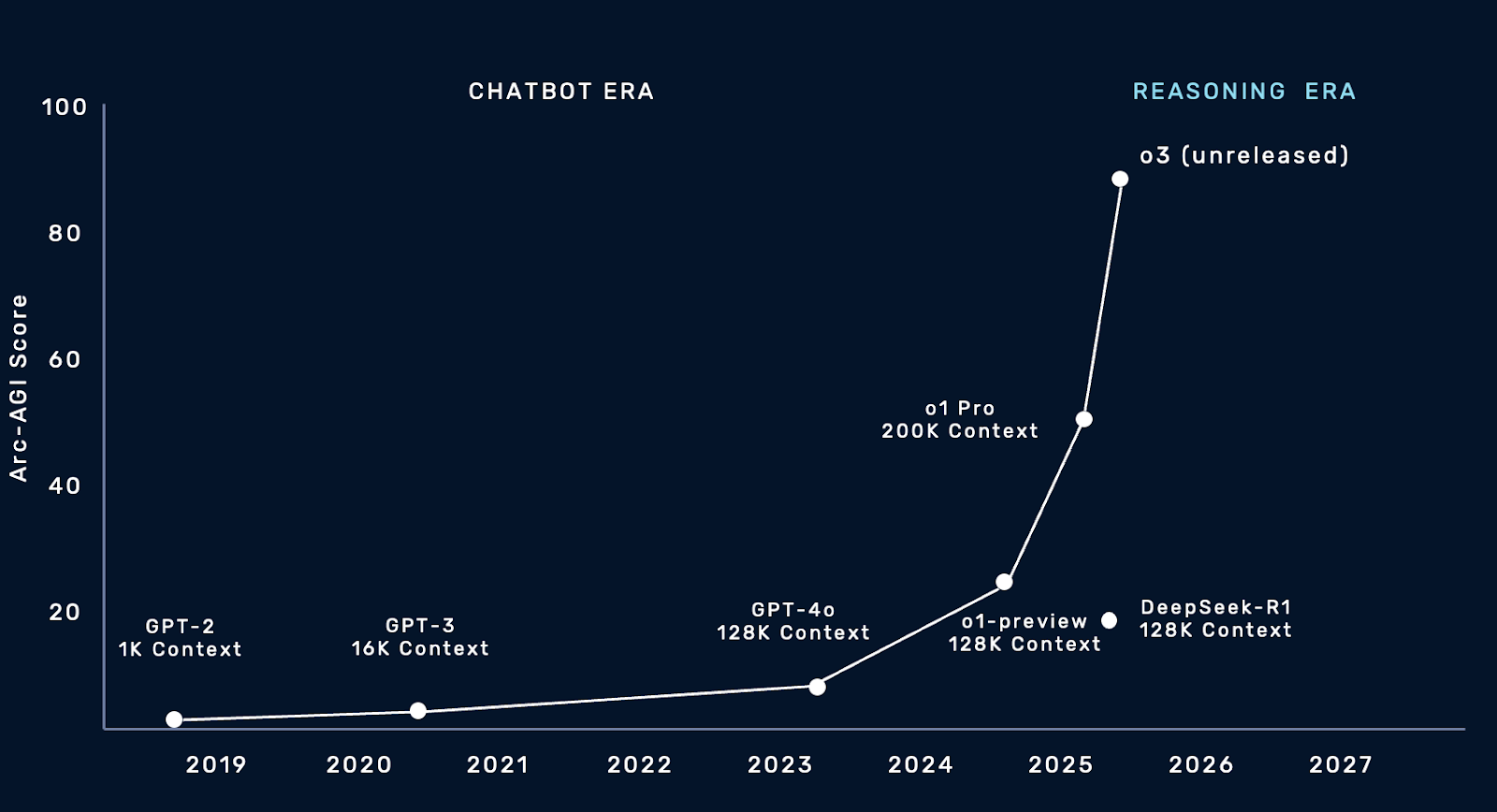
From a product angle, many players—large and small—focus on accelerating smaller models with high arithmetic intensity. These models have modest context lengths, like standard chatbots. When deploying the largest models, engineers are forced to distribute inference workloads over hundreds of chips, which leads to inefficiencies. Rain AI’s different. We’re not designing a general-purpose solution for any model or operation. We’re zeroed in on the largest models with massive context—these giant reasoning models like o3 and R1 which have very low arithmetic intensity. We believe that’s where AI is headed over the next 18 months, and we want to be the hardware vendor that handles those complex workloads efficiently.
Rain AI’s different. We’re not designing a general-purpose solution for any model or operation. We’re zeroed in on the largest models with massive context—these giant reasoning models like o1 and agentic workloads. We believe that’s where AI is headed over the next 18 months, and we want to be the hardware vendor that handles those complex workloads efficiently.
Technically, the bottleneck in running the largest AI models has shifted to memory, yet every chip company is still focused on optimizing compute. This includes the major public semiconductor companies, hyperscalers, and chip startups. Unlike the competition, we are focused on solving AI’s memory problem.
Our architecture maximizes memory capacity and bandwidth via novel techniques to handle these huge models. Others might still chase emerging computing techniques or be tied to certain memory hierarchies that won’t scale to next-gen models and applications. We’re building for the big picture: enormous models, unprecedented scale.
J-D:
Some companies try to address memory bandwidth issues differently, but from what I’ve seen, their methods have scalability limits. For the massive models we aim to support, those limits become real roadblocks. Our compute-in-memory approach ensures we can scale and jump to new process nodes. This sets us apart from others who might find themselves stuck with approaches that don’t evolve as fast as AI demands.
Congrats on having working chips. You also mentioned “taping out” a chip on TSMC’s 6nm node. What does that mean and why is it a big milestone?
J-D:
“Taping out” means we finished designing the chip and we send that design to TSMC to actually fabricate the silicon. TSMC is the world leader in advanced semiconductor processes. By taping out in their latest node, we’re leveraging the best process technology available, which helps with scaling and efficiency.

Ross:
We now have working chips. Our Puget Sound system-on-chip (SoC), built on TSMC 6nm, has successfully validated our core technology. It integrates our digital compute-in-memory, a customized RISC-V core, and other custom IP blocks. Puget Sound demonstrates our ability to push compute under tight thermal constraints—a key enabler and foundational building block for our commercial chip, “Ocean Beach”. It is also a huge step for our software. We can already write models in Torch and compile them to run on Puget Sound. Our software team will now use Puget Sound as a test platform to refine our software stack for Ocean Beach.
What does the roadmap look like for the next 6–12 months and beyond?
J-D:
Ocean Beach is a data center post-training and inference accelerator specifically tailored for reasoning models and agents. We believe agents—which can autonomously take complex actions—are the next leap for AI, and reasoning models are the key enabler. Reasoning models are far more memory-bound than traditional chatbots. To accommodate larger context windows and longer “thinking” time (called decode), Ocean Beach couples compute and memory very closely—more closely than GPUs do. This increases overall memory capacity and eliminates bottlenecks faced by standard GPU designs. Ocean Beach will be commercially available in 2026.
On the people front: I’ve built a strong, experienced team from the best companies out there—people who know how to design chips and deliver them on time. After we staff up even more, we’ll maintain a disciplined, focused approach to hiring, ensuring everyone fits culturally and technically.
J-D, you said your personal mandate at Rain AI was: delivering chips on time, just like at Apple. How do you see that playing out at a startup?
J-D:
It’s exactly that. At Apple, we never missed a tape-out. That discipline and systematic approach to chip design—ensuring everything is methodical, rigorous, and on schedule—I’m bringing all that to Rain AI. I’m also introducing techniques learned from building ultra-low-power SoCs at Apple, which had extreme performance and power constraints. Many of those low-power techniques and design philosophies apply directly to Rain AI’s inference engine. The goal is to make our product not only powerful but also incredibly power-efficient.

Ross:
Bringing J-D onboard instantly changed the cultural dynamic. We are intensely focused on execution, which is invaluable for a startup transitioning from R&D to commercialization.
Speaking of culture, what’s the team’s size and hiring philosophy? Who are you looking for in terms of both culture and technical skill?
J-D:
When I joined, it was more or less a skeleton crew. My philosophy is not to build huge armies of engineers but small, agile teams where each person is highly capable and versatile. We’re already staffing up well, and I expect we’ll continue to hire over the next six months. After that, we’ll be very selective, only adding people who fit both technically and culturally. Cultural fit matters a lot—technical brilliance means nothing if someone doesn’t mesh with our way of working.
Ross:
We’ve hired some of the best—people from Nvidia, Apple, Broadcom, SpaceX, Google, Meta. Interest has surged in the last few months. Despite that, we’re picky. We want low-ego, highly collaborative folks. If someone can’t operate as part of a team or respect others, we don’t bring them on, no matter their résumé. We’re proud of the talent and even prouder of the culture we’re building—one that balances technical excellence with genuine collaboration and mutual respect.
J-D:
If someone’s excited about AI and wants to build something groundbreaking, they should consider reaching out. We’re working on truly exciting tech.
Conclusion
Stay up to date on the latest with Rain AI, learn more about them here.
Read our past few Deep Dives below:
If you would like us to ‘Deep Dive’ a founder, team or product launch, please reply to this email ([email protected]) or DM us on Twitter or LinkedIn.